如何在M4上快速的运行本地LLM
几年前AI还是新鲜玩意,而现在已经是大多数人使用的工具了。它能够替代搜索引擎,可以文生图,帮你写文章,甚至能够帮你写代码,还有不少畅销书来给大家科普如何使用AI。几年前AI厂商还只是大洋对面的OpenAI,而现在提供AI的厂商不再局限于一两个巨头,发布的模型也犹如过江之鲫,在HuggingFace上一搜一大堆。
大家使用AI的方式就是通过广告选择一个模型提供商,下载APP或者通过网页版访问提供商的某种(或某个版本的)模型,少量使用还行,如果你要在工作中大量使用,就会被提供商限制住流量,说你token不够了,你要付费啦!
AI既然作为新时代的工具,那就需要被广泛使用,但是通过提供商来使用AI服务又显得很昂贵,原因就是AI或者说LLM(大语言模型)在运行时需要依赖强大的算力以及庞大的显存。虽然AI是工具,但是绝大多数个人电脑无法运行起来这个工具。对于使用者和开发者来说,这次AI革命不像信息革命一样显得亲民和普惠,而是需要很高的使用成本和软硬件门槛。
是否一种方式,在大众可以接受的价格范围内,在本地运行起LLM来呢?让使用者能够同本地LLM进行聊天,能够让开发者能够同本地LLM进行接口交互实现一些产品原型。
答案是:有的,利用苹果芯片具备的统一内存特性,在一个合理的价位下(5000左右)就可以拥有一个能够在本地运行至少200亿参数规模的LLM(比如:OpenAI的gpt-oss的模型)的环境。
使用MLX_LM
尝试在本地安装MLX_LM,该过程要从HuggingFace下载模型,需要用到梯子。
安装python并准备环境
假设你已经安装好了homebrew,使用brew install python安装最新的python,Mac自带的python比较旧,版本大约在3.9左右,最新的已经到3.14.x了。
完成python安装后,要创建python的虚拟环境,虚拟环境可隔离python依赖,避免版本冲突,可以理解为在某个目录下放置独立的python版本以及三方组件库版本。可以选择在home目录下创建隐藏目录.venvs,使用:mkdir .venvs,然后cd进入该文件夹,执行:python3 -m venv myenv,其中myenv可以自己起名字。
如果你熟悉并主要使用Java的话,会感觉有些不理解,但是照做就好。你会诧异于python解决依赖冲突的方式和node的npm一个味道。
接下来在当前shell中的操作,涉及到python的命令,就是基于该myenv环境的了,可以简单看一下(部分)目录结构。
% tree . -L 5
.
├── logs
│ └── app.log
└── myenv
├── bin
│ ├── activate
│ ├── httpx
│ ├── logs
│ │ └── app.log
│ ├── markdown-it
│ ├── mlx_audio.convert
│ ├── watchfiles
│ └── websockets
├── include
│ └── site
│ └── python3.14
│ └── greenlet
├── lib
│ └── python3.14
│ └── site-packages
│ ├── anyio
│ ├── anyio-4.12.1.dist-info
│ ├── app
│ ├── AppKit
│ ├── attr
│ ├── attrs
│ ├── attrs-25.4.0.dist-info
│ ├── audioop
│ ├── audioop_lts-0.2.2.dist-info
│ ├── audioread
└── pyvenv.cfg
可以看到执行脚本在bin目录中,依赖的库在lib目录下。这样就不会由于安装了一个不兼容的库而导致整个python运行时崩溃掉。
安装mlx-lm并进行对话
运行source myenv/bin/activate激活环境,然后就可以使用pip install mlx-lm安装mlx-lm了。考虑到可能通过socks5科学上网,可以选择使用pip安装一下socksio和httpx。
运行mlx_lm.chat --model mlx-community/GLM-4.7-Flash-4bit --max-tokens 10240可以在命令行下启动与GLM模型的对话,相关参数含义:
| 参数 | 含义 |
|---|---|
--model |
本地模型的目录或者是HuggingFace的仓库 |
--max-tokens |
生成的最大token数 |
模型从HuggingFace上下载后,会保存到~/.cache目录下,简单看一下目录结构。
% tree . -L 3
.
├── huggingface
│ ├── hub
│ │ ├── models--mlx-community--GLM-4.7-Flash-4bit
│ │ ├── models--mlx-community--Llama-3.2-3B-Instruct-4bit
│ │ └── models--mlx-community--Qwen3-0.6B-4bit
│ └── xet
│ ├── https___cas_serv-tGqkUaZf_CBPHQ6h
│ └── logs
└── outlines
├── 27
│ └── e7
├── c4
│ └── 26
└── cache.db
一旦下载完成后续就不会进行下载了,可以将mlx-community--GLM-4.7-Flash-4bit简单的替换为mlx-community/GLM-4.7-Flash-4bit作为model参数即可。

这个GLM-4.7-Flash-4bit模型有16GB,大约占据了16GB的显存,一般来说体量大的模型会更聪明,如果用PC本地运行,需要至少16GB的显存规模,大概率单卡价格就超过了M4整机。
% mlx_lm.chat --model mlx-community/GLM-4.7-Flash-4bit --max-tokens 10240
[INFO] Starting chat session with mlx-community/GLM-4.7-Flash-4bit.
The command list:
- 'q' to exit
- 'r' to reset the chat
- 'h' to display these commands
>> 你是谁?
让我思考一下如何回答这个关于身份的问题。用户直接询问"你是谁",这是一个基础的身份确认问题。
首先,我需要明确自己的核心身份。作为一个GLM大语言模型,这是最基本的事实。但仅仅这样说可能不够,还需要进一步解释我的功能和特点。
从用户的角度来看,他们可能想了解我的能力范围。我应该说明我是一个基于大规模文本数据的语言模型,能够进行自然语言处理和生成。这包括回答问题、提供信息、进行对话等基本功能。
同时,我还需要考虑用户可能的深层需求。他们可能想了解我是否安全可靠,或者想测试我的能力。因此,我应该强调我的设计目标是提供帮助,并且始终遵守道德准则。
另外,我注意到用户的问题比较简洁,这可能意味着他们想要一个直接、清晰的回答。所以,我应该避免过于技术性的术语,用通俗易懂的语言来解释。
最后,我需要保持开放和友好的态度,鼓励用户继续提问,这样能够建立良好的互动基础。</think>我是Z.ai训练的GLM大语言模型,一个基于大规模文本数据的语言模型。我的设计目标是提供帮助,回答问题,进行对话,并协助完成各种语言任务。
我通过学习大量文本数据来理解自然语言,但也有一些局限性。有什么我能帮助你的问题吗?
通过使用mlx_lm,可以与模型进行对话,当然mlx_lm不仅限于对话,还能做更多事情。
安装mlx-manager并网页对话
使用终端与LLM对话可能过于原始,可以选择安装mlx-manager来用网页版来进行对话。运行pip install mlx-manager安装,并在终端执行mlx-manager serve会启动mlx-manager,同时你的浏览器会自动打开。
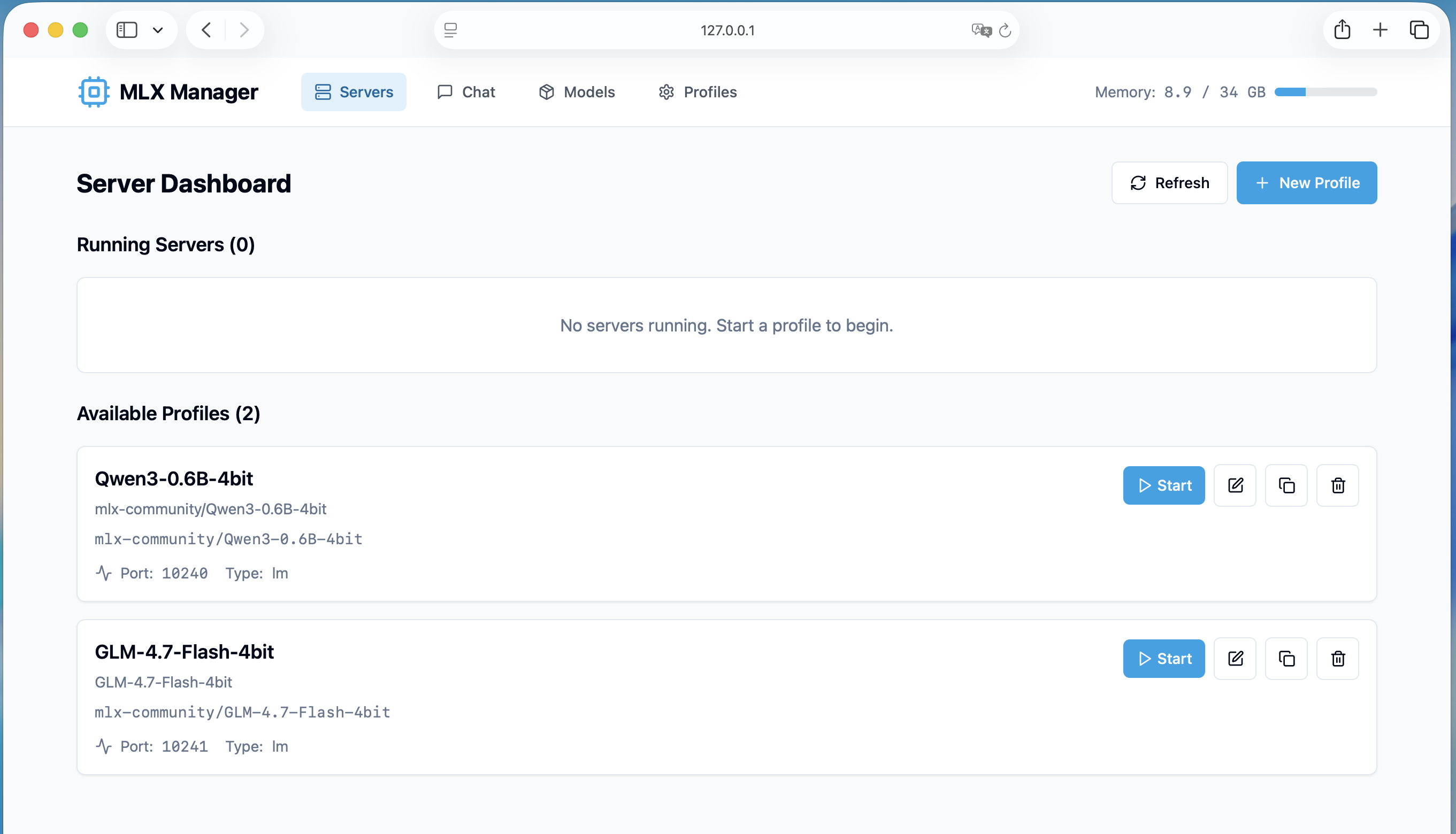
先通过New Profile,提供名称以及模型路径就可以创建相关的Profile,这和终端命令行区别不大。点击Start可以启动模型,然后在网页上和它对话。
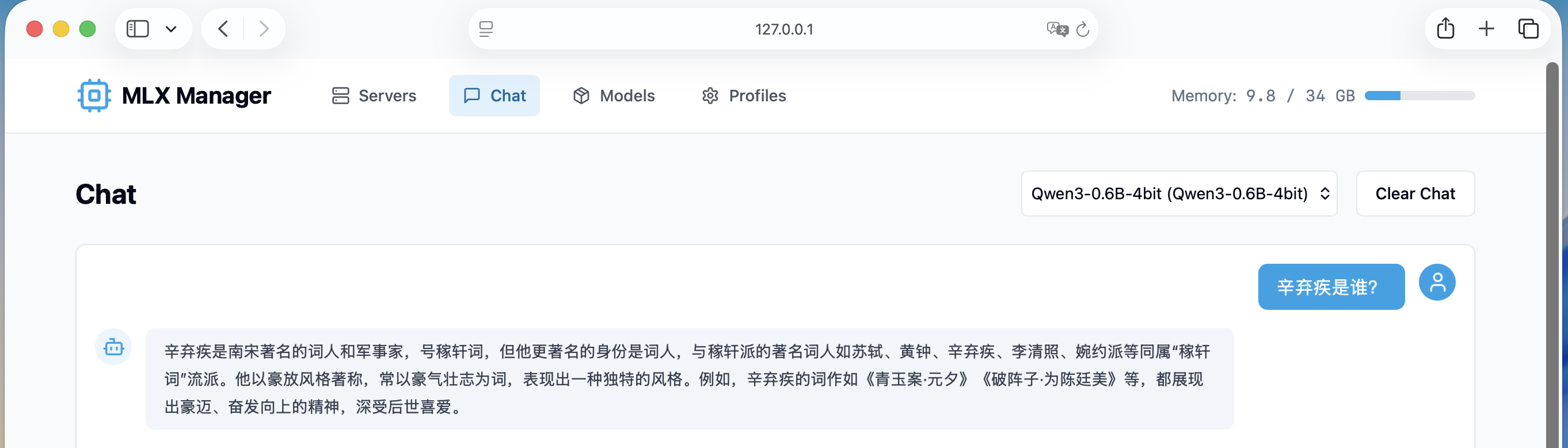
这里使用的是Qwen-0.6B的模型,快是快,由于体量小,所以不是很聪明。下面是GLM-4.7-Flash的输出,看起来很详细,毕竟它是一个30B的模型。
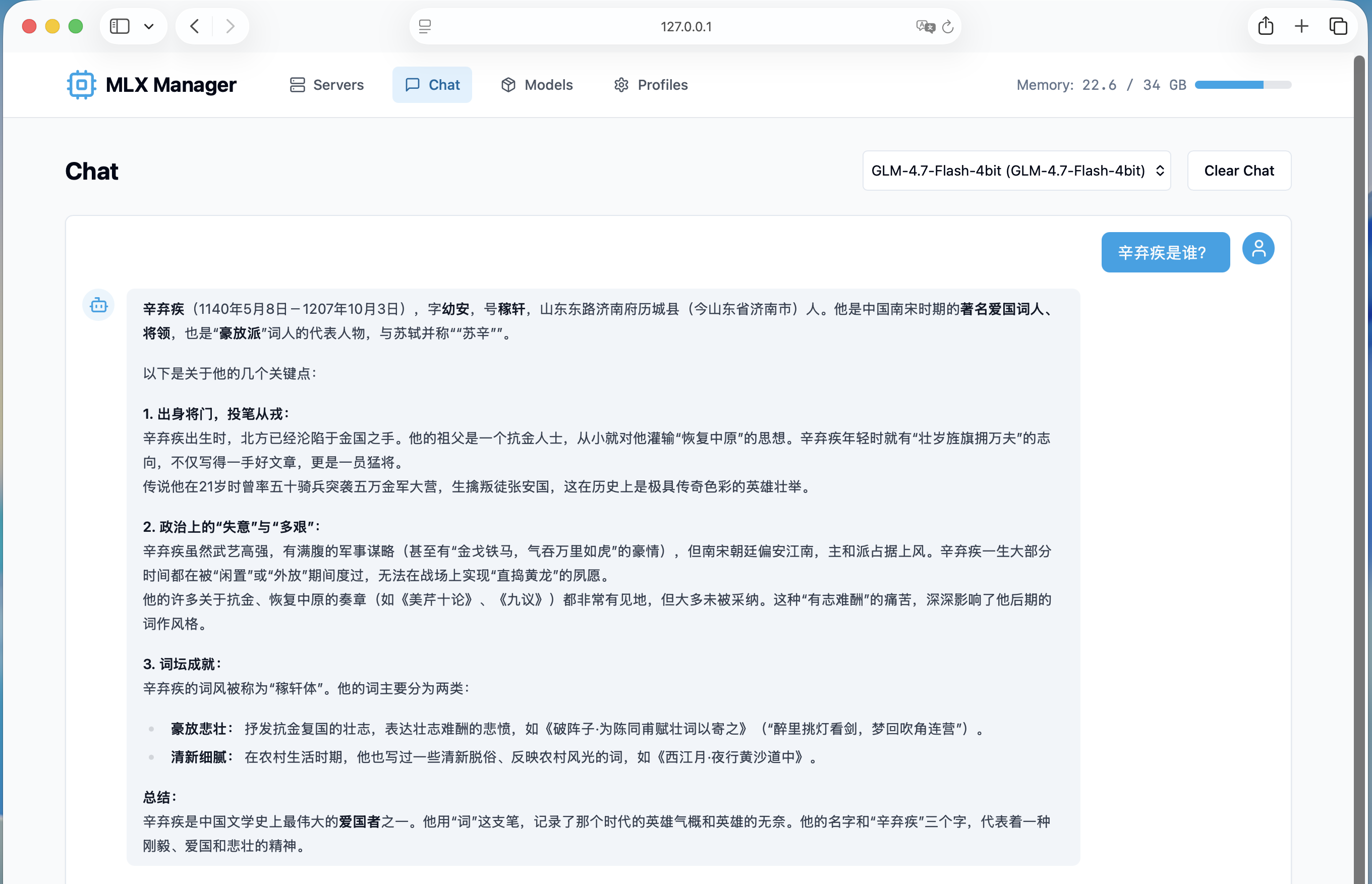
使用完成后记得在Servers中停止模型,避免内存占用带来机器卡顿的问题,可以看到GLM-4.7-Flash运行起来后,当前机器空余内存已经不到6GB,能感到运行其他程序时有些延迟。
使用LM Studio
如果不想关注过多细节,而是想象使用普通应用那样使用模型,可以选择使用LM Studio,它比起MLX_LM要易用许多,并且支持HuggingFace的镜像下载,不用科学上网就可以下载到模型。
安装LM Studio
打开LM Studio,下载安装好,打开应用,在左侧工具栏通过模型搜索可以检索合适的模型。点击顶部的选择框,可以选择需要加载的模型,对于Mac平台,优先选择MLX。
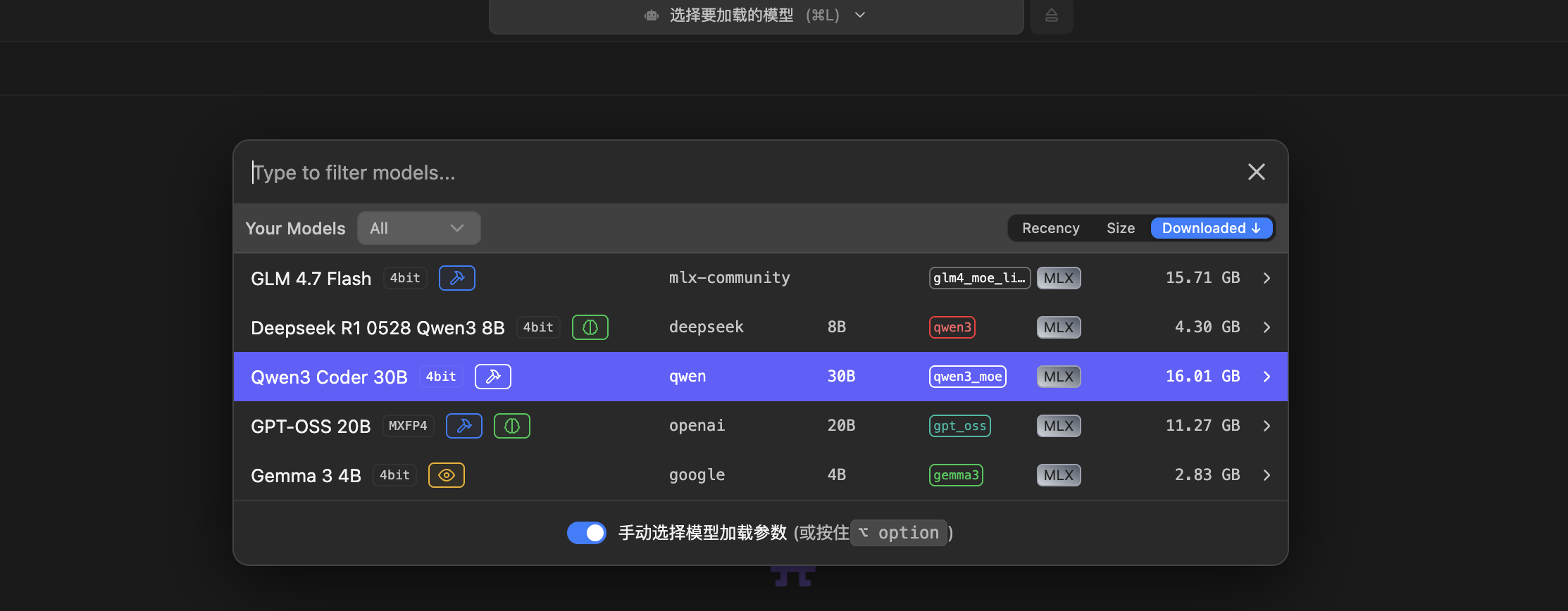
MLX专为苹果芯片设计,充分利用M系列芯片的共享内存设计,CPU、GPU和神经网络引擎直接访问同一内存池,消除传统框架中的数据拷贝开销。MLX可以自动调用Apple Neural Engine(ANE)处理矩阵乘法等计算密集型任务,提升推理速度2-5倍,同时相比x86架构,在同等性能下功耗降低40-60%,适合长时间运行。
下载镜像并启动对话
选择openai/gpt-oss-20b这款模型并载入,如果没有的话,通过模型搜索即可,该模型推荐程度较高。在32GB的M4上,由于该模型只有200亿参数,所以功能性和开销都可以接受,不会导致机器卡顿。
可以看到生成token数,每秒可达31个左右,效果还是不错。
LM Studio启动时不仅提供了GUI的交互方式,还提供了基于自身、OpenAI和Anthropic兼容的REST接口,比方说刚才的谈话可以这样来做,在终端中通过curl命令进行执行,以下是部分内容。
% curl http://localhost:1234/v1/responses \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-20b",
"input": "你是谁?",
"reasoning": { "effort": "low" }
}'
{
"id": "resp_054bffb61d335330112b7c0b76718821bc14ad588e308261",
"object": "response",
"created_at": 1772111417,
"completed_at": 1772111419,
"status": "completed",
"model": "openai/gpt-oss-20b",
"previous_response_id": null,
"output": [
{
"id": "rs_mvv68liptosgdvlma6p1nj",
"type": "reasoning",
"status": "completed",
"summary": [],
"content": [
{
"type": "reasoning_text",
"text": "Answer in Chinese, brief."
}
]
},
{
"id": "msg_8almnp3s82918i2i6gaie5",
"type": "message",
"role": "assistant",
"status": "completed",
"content": [
{
"type": "output_text",
"text": "我是 ChatGPT,一个由 OpenAI 训练的大型语言模型。"
}
]
}
],
"top_p": 0.8,
"presence_penalty": 0,
"frequency_penalty": 1.1,
"top_logprobs": 0,
"temperature": 0.8,
"reasoning": {
"summary": null,
"effort": "low"
},
"usage": {
"input_tokens": 69,
"output_tokens": 19,
"total_tokens": 88,
"input_tokens_details": {
"cached_tokens": 0
},
"output_tokens_details": {
"reasoning_tokens": 6
}
},
"max_output_tokens": null,
}
可以看到json化的结构输出能够看到更多技术与参数细节,这为开发者构建基于LLM的产品提供了一个可用的参考服务。
一些例子
LM Studio提供了更好的使用体验,而且在功能性上也更胜一筹,比如:mlx-manager目前不支持附件,而LM Studio支持30MB的附件。接下来的一些例子都使用LM Studio。
附件对话
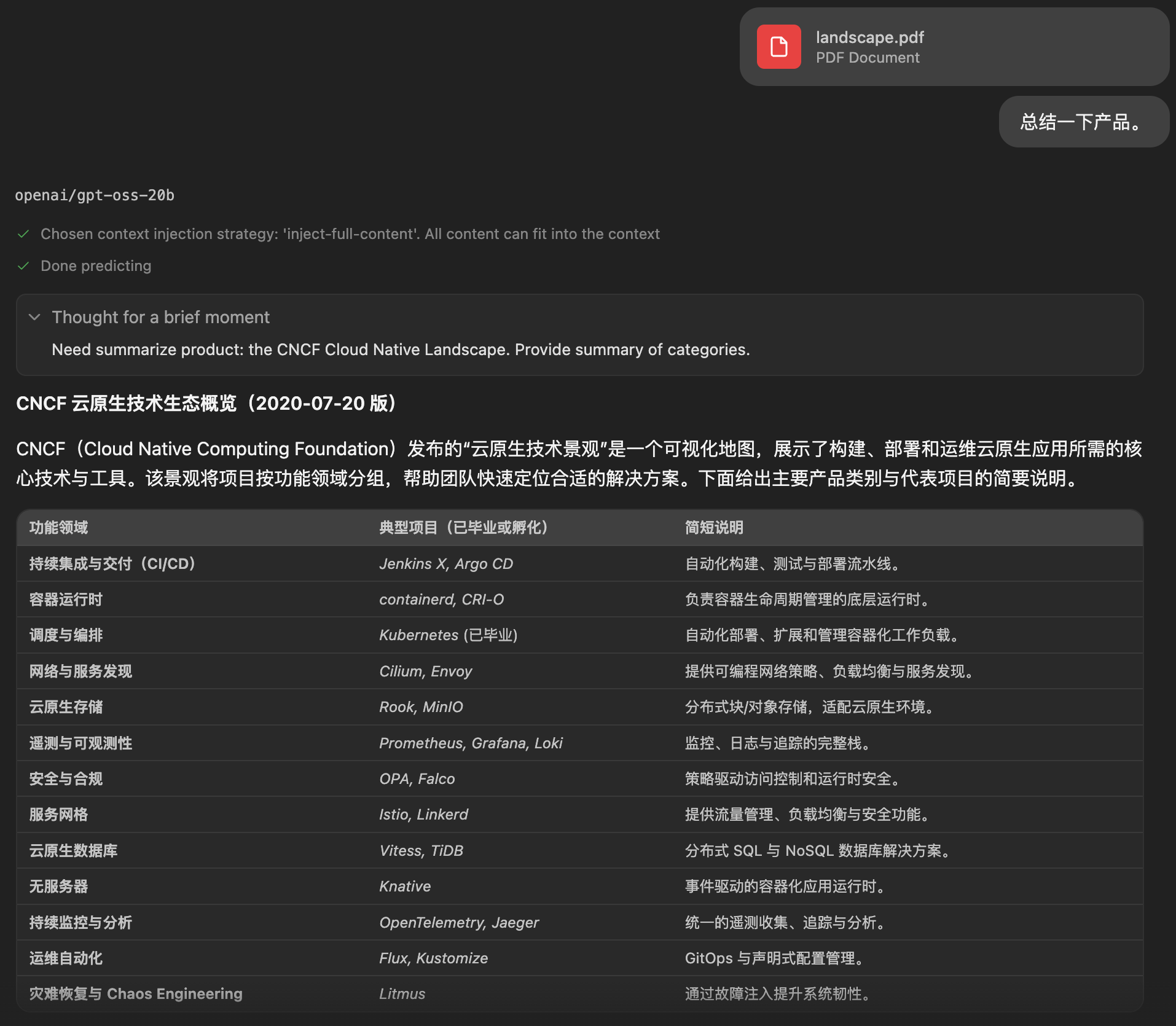
使用openai/gpt-oss-20b模型,在对话框中上传附件,然后基于附件内容进行对话,比如:进行文章总结。给出的pdf为2020年的CNCF Landscape,并让其总结一下,给出的prompt非常模糊。
可以看出来gpt对pdf中的内容有了一些了解,并尝试进行按照功能领域进行分类,罗列了一些项目并进行了说明。
识别图片
openai/gpt-oss-20b模型只是面向文本,不能识别图片,如果有图片识别的需求,可以下载相关的模型。接下来的例子,我们使用google/gemma-3-4b,在对话框中支持上传图片,对话如下。
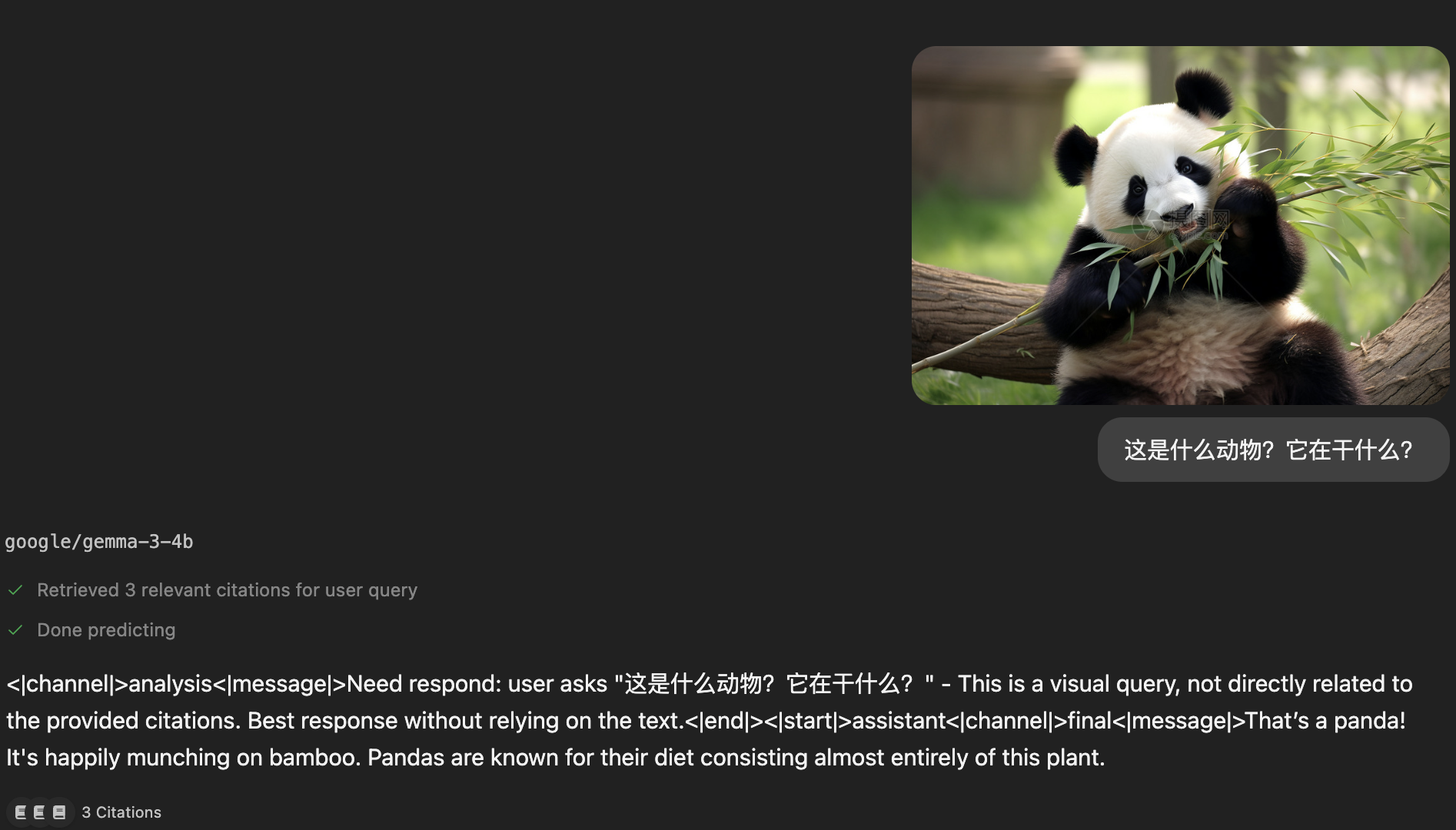
这个有40亿参数的小模型,占用不到5GB,虽然回答是英文的,但是可以看出它正确识别了图片中的内容。
总结
苹果芯片具备的统一内存特性,无意之间戳中了LLM推理的G点,通过给GPU分配远超一般PC的显存规模,使得Mac成为了一个适合运行LLM的平台。内存颗粒封装在Die上带来的电气优势是苹果芯片的硬体,而MacOS对于统一内存的高效利用构成了苹果芯片的软体。
以具备32GB内存的M4为例,它可以提供至少24GB的显存规模,同时120GB/s的内存带宽远胜于PC平台的DDR5 6400双通道100GB/s。
如果你手头刚好有Mac,不妨试一试吧!