JavaNetwork's TcpDump与Redis客户端
在处理网络问题时,我们可以使用抓包工具进行抓包,通过分析数据包来了解问题发生时的网络状况,从而定位和解决问题。Wireshark无疑是使用最广泛的抓包工具,它具有漂亮的GUI界面,丰富的功能菜单,在本机上可以随时开启和暂停它,但是如果环境切换到服务器上,可能就没那么顺利了,毕竟你难以在服务器上安装一个wireshark,更何况现在的服务端应用大都跑在容器里。
此时你需要一款小巧的工具,它可以按照你的要求进行抓包,比如:指定目标IP或者端口等,将抓包的内容输出到文件中,你甚至可以将文件拽回到本地,再使用wireshark打开分析,这款工具就是tcpdump。在一般的Linux发行版中,都会携带tcpdump,所以使用起来很容易。tcpdump是基于libpcap来工作的,后者是抓包库,它能按照你的要求将网卡上的包发给对应的程序,而在本文中,这个程序就是tcpdump。
tcpdump提供了一套形式化的描述逻辑,用户将需求翻译成这些描述逻辑后,tcpdump会理解这些逻辑,并使用libpcap将符合要求的包记录下来给到tcpdump,用户可以选择将这些包输出到控制台或者文件中。
使用tcpdump抓取一次curl
接下来使用tcpdump抓取一次HTTP请求,首先通过ping找到www.bing.com的IP是:202.89.233.100,然后在终端运行命令:tcpdump -i en0 host 202.89.233.100 and port 80 -nn,此时终端会等待输出。新开一个终端,运行命令:curl -v www.bing.com,这表示会对www.bing.com完成域名解析,同时再对相应的IP发起HTTP请求并输出响应。
-i 用来指定网卡,比如当前系统的网卡标识是en0
host 用来指定目标IP,也就是只有目标IP是host指定的数据包才会被拦截
port 用来指定目标端口
-nn 用来取消网络设备的名称解析,这样就直接展示IP,而不是主机名
and/or 与/或表达式,如果有多个条件,需要灵活使用and和or
请求并输出内容如下:
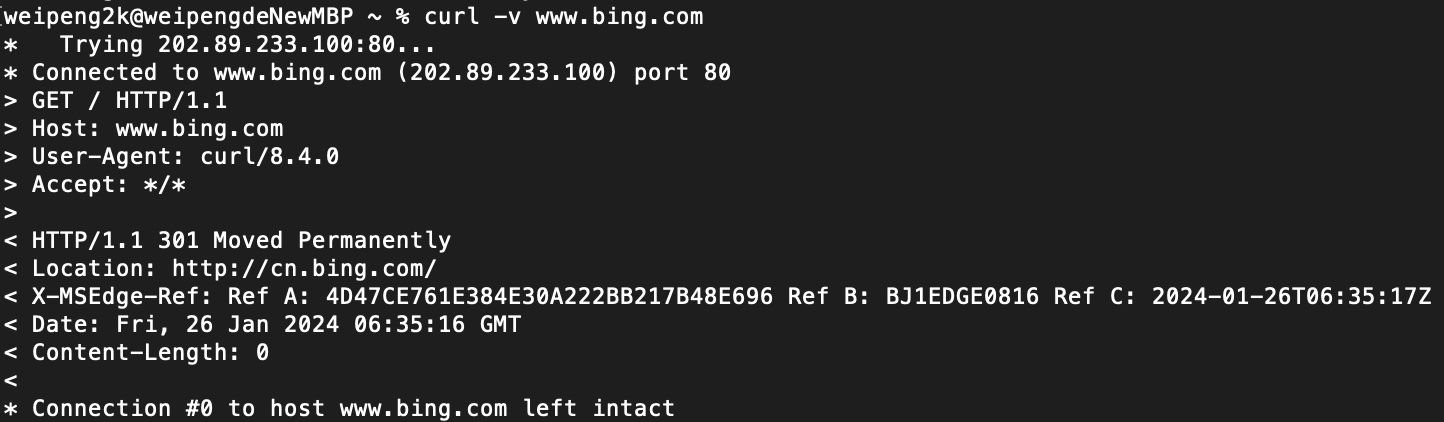
可以看到访问www.bing.com,服务端返回了301,将请求重定向到http://cn.bing.com。此时先前运行tcpdump的终端有了输出,如下所示:

看来tcpdump已经通过libpcap拦截到了我们期望的数据包,并将相关内容输出到控制台,可以看到过滤器收到了59个数据包,而符合要求的有11个。每个数据包占一行,其中第一列为时间,接着是来源IP与端口,以及目标IP与端口。Flags是TCP报文中的控制位,其中S代表SYN报文,.代表ACK报文,P代表PSH报文,F代表FIN报文。
前三个数据包是TCP建连过程,以第一个数据包为例:seq是3143996361,mss是1460字节。接着对端回复SYNACK报文,ack是3143996362,而mss是1440字节。最后四个数据包是TCP断开连接的过程,也就是我们熟知的四次挥手。中间的4个数据包就是HTTP消息通信的过程,可以看到主机发送了GET请求,而对端回复了HTTP状态码为301的响应。
导出cap文件并用wireshark打开
使用tcpdump可以将需要拦截的数据包输出到控制台上,同样也可以将其保存在文件中,并且使用wireshark打开。假设拦截网卡en0上所有的包,并将其输出到en0.cap文件中,可以执行命令:tcpdump -i en0 -w ~/Desktop/en0.cap,执行命令后,可以打卡浏览器访问几个页面,然后退出tcpdump程序,过程如下图:

可以看到通过tcpdump拦截了近9千个数据包,其实也就是访问了两个网站,不超过五个页面,接着可以使用wireshark打开en0.cap文件,可以看到界面是这样的。
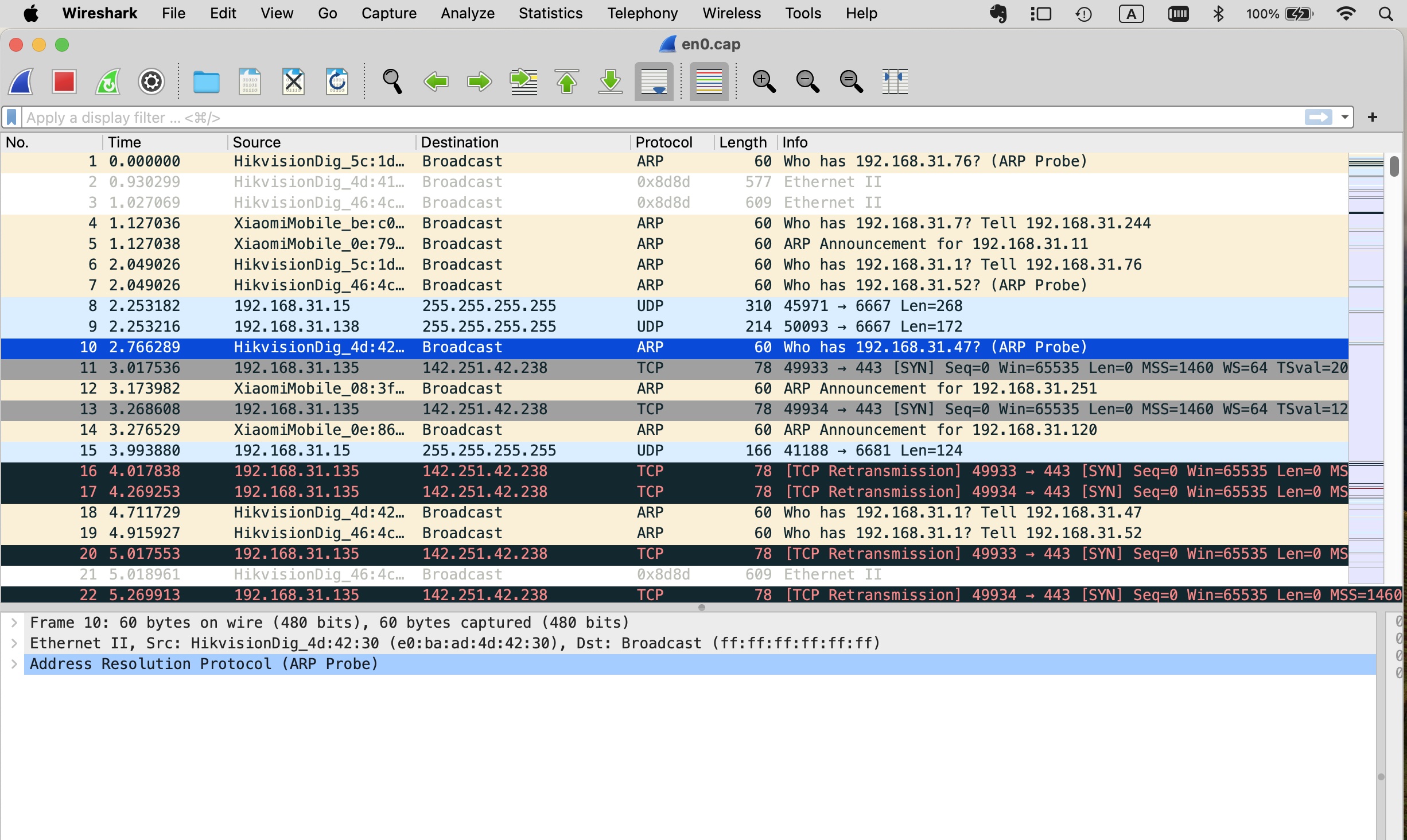
如上图所示,本地网络存在许多不同类型的设备,这就使得网络中充满了各式各样的数据包,它们使用的协议有ARP,也有DNS,还有访问资源的TCP等等,显得非常嘈杂。这样我们就可以在服务器端使用tcpdump抓去数据包,将抓到的数据包保存到文件中,然后将文件拽到本地后使用wireshark打开分析。
两个redis客户端
Redis是目前后端最流行的缓存服务,由于它是一个开放协议的server,所以不同语言有不同的客户端。以Java的Redis为例,常见的就有Jedis和Lettuce,它们都可以操作Redis服务,性能孰强孰弱呢?这里我们不去比拼实现,而是通过抓包来看一下,在抓包之前,基于两个客户端,看一下测试代码。
使用jedis
Jedis客户端选择的版本是3.2.0,其I/O基于原生Java实现,使用方式参考其文档,单线程的set和get,代码如下:
/**
* Jedis cost:410630ms.
*/
@Test
public void writeAndRead() {
long start = System.currentTimeMillis();
IntStream.range(0, 10_000)
.forEach(i -> {
jedis.set("redis" + i, String.valueOf(i));
jedis.get("redis" + i);
});
System.out.println("Jedis cost:" + (System.currentTimeMillis() - start) + "ms.");
}
可以看到对于1万个KEY的设置和获取,耗时在410秒左右,因为Jedis客户端是线程不安全的,所以我们只能比拼单线程场景,如果要测试多线程场景,就需要使用Jedis连接池,相较于Lettuce而言,这其实对Jedis更不利。
使用Lettuce
Lettuce客户端选择的版本是6.3.1.RELEASE,其I/O基于Netty实现,使用方式参考其文档,单线程的set和get,代码如下:
/**
* Lettuce cost:349684ms.
*/
@Test
public void writeAndRead() {
long start = System.currentTimeMillis();
IntStream.range(0, 10_000)
.forEach(i -> {
syncCommands.set("REDIS" + i, String.valueOf(i));
syncCommands.get("REDIS" + i);
});
System.out.println("Lettuce cost:" + (System.currentTimeMillis() - start) + "ms.");
}
可以看到对于1万个KEY的设置和获取,比Jedis快了差不多1分钟。
tcpdump分析两个redis客户端
在执行测试前,运行命令:tcpdump -i en0 dst port 23877 or src port 23877 -nn -w ~/Desktop/jedis.cap,这个命令生成一个jedis.cap的抓包文件,同时捕获来自网卡en0的数据包,如果来源或目标端口都是23877时,符合捕获的条件。
分别抓取了jedis.cap和lettuce.cap两个文件,然后通过wireshark进行分析,在统计菜单中,吞吐量一栏,可以看到如下对比:
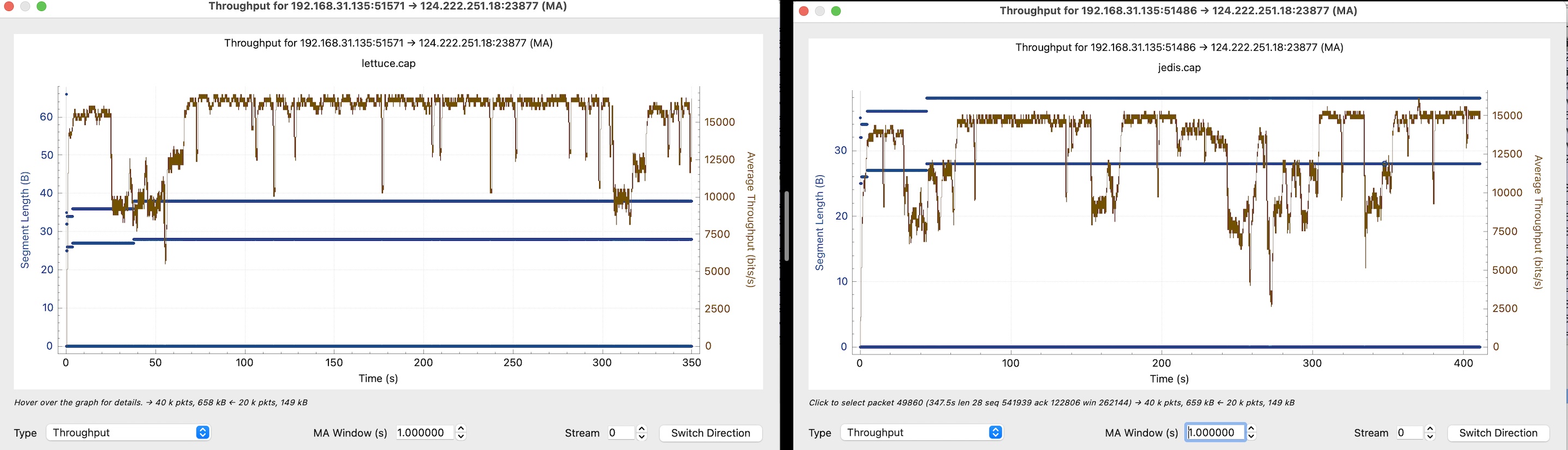
可以看到,lettuce要比jedis表现稳定且高效的多,直接原因是Netty要比Java原生socket库更为优秀,使得在处理拥塞控制时更加出色,进而获得了更好的吞吐量。lettuce每次拥塞发生时,都会很快的拉起吞吐量,而jedis面对拥塞,有很长的拥塞避免阶段,甚至出现了在200秒到300秒之间退化到慢启动阶段的情况。综上所述,在lettuce和redis之间的选择压根不用考虑,一定是前者,至于云厂商不负责任的宣传,那是因为云厂商不规范的部署拓扑导致的,和产品无关,只需要加上TCP的keep-alive即可解决主从切换引发的无法工作问题。