感悟《计算机网络:自顶向下》(03a.传输层)
传输层简介
传输层位于TCP/IP五层结构中自顶向下的第二层,它向上提供socket编程接口,为应用层服务提供面向网络的编程界面,向下使用网络层提供的服务进行数据传输。传输层为运行在不同主机上的应用进程提供逻辑通信的能力,同时为了让应用层尽可能少的关注到网络传输细节,还支持流量控制和拥塞控制,使其能够最大限度的支持应用层对于网络服务的诉求。
结构
Socket作为传输层的编程界面,其实现由不同的操作系统各自提供,但是socket编程方式大都相似,这是因为传输层从标准上分为了面向连接的TCP和面向用户数据报的UDP,由于是标准协议,所以在行为上基本类似。不同的语言会封装不同的接口以及提供数据结构来支持socket编程,但它们的底层实现都会依赖具体操作系统的API,直白点就是,任何语言的网络编程本质上都是系统编程。系统API的实现是来自不同操作系统的协议栈程序,应用程序透过socket与网络的交互,实际上都是和本地协议栈程序的交互,委托它与对端系统(的协议栈程序)进行通信,上述过程如下图所示:
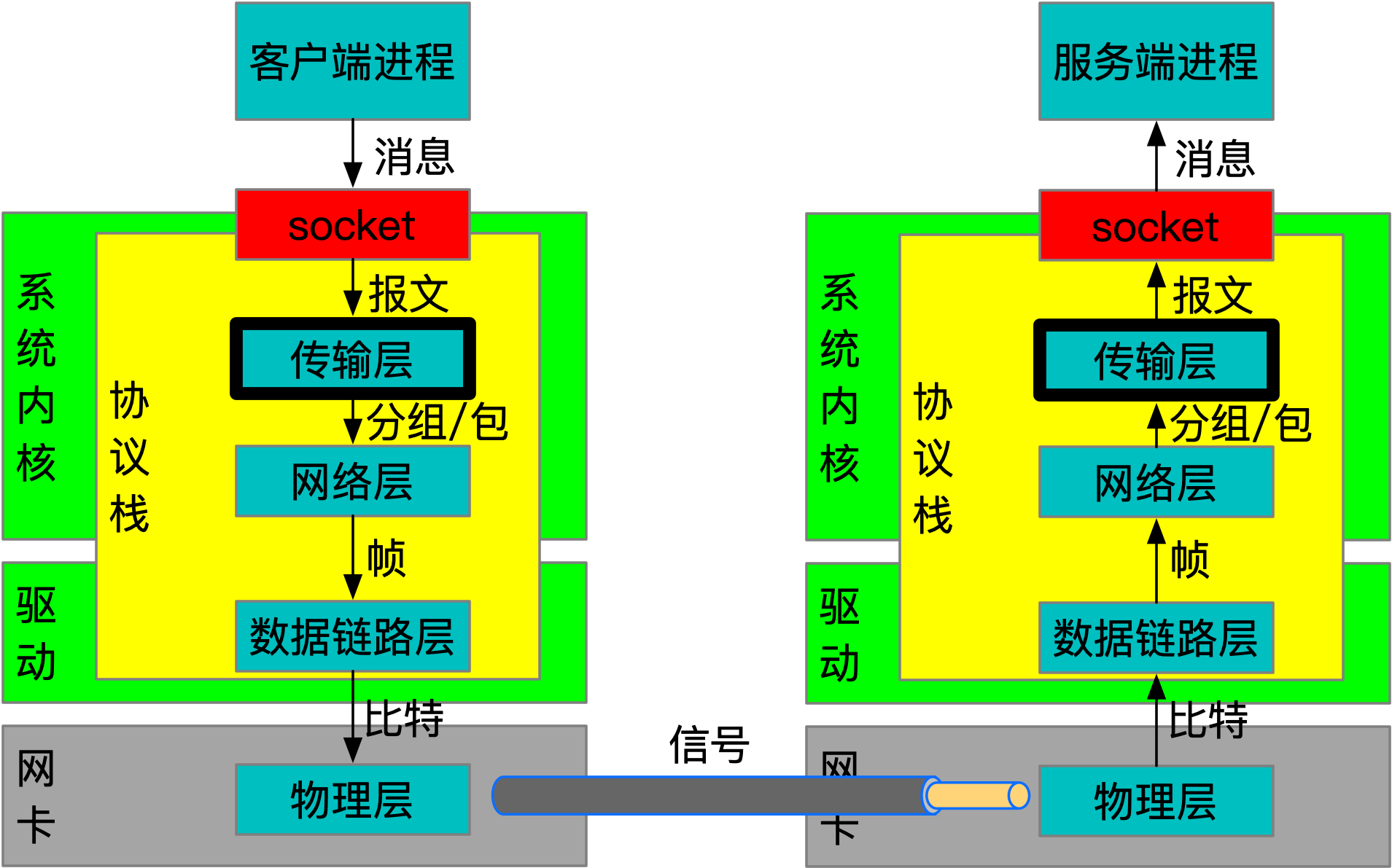
可以看到传输层是联通应用与操作系统协议栈的桥梁,也是网络编程的起点,它以软件的方式支持了应用层的构建。
TCP和UDP
TCP是面向连接的传输层协议,它能够提供可靠的传输服务,UDP不是面向连接的传输层协议,传输服务不可靠。UDP叫用户数据报协议,啥叫用户数据报?可以看看下图:
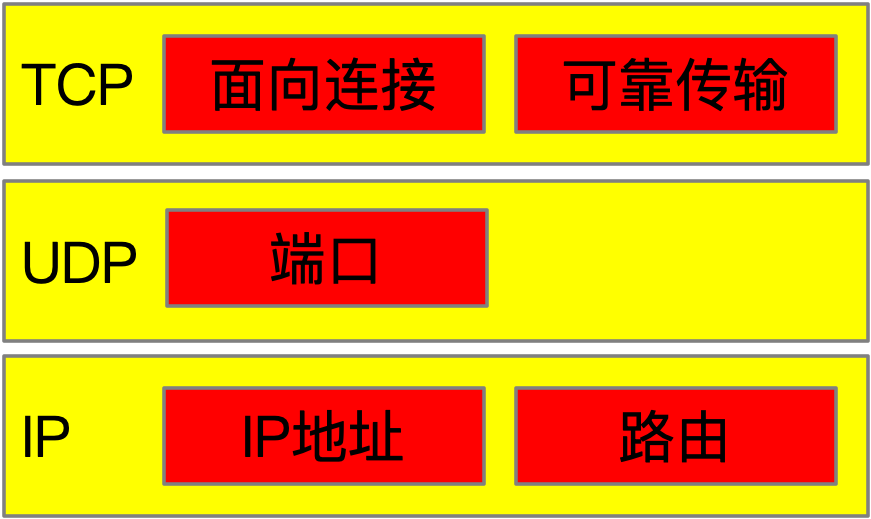
如上图所示,UDP相当于在IP之上增加了对端口(进程)的支持,时髦的话可以这么说:为基于IP的网络服务提供了租户(或命名空间)的概念,进一步赋能了网络层。网络层进行通信的数据单元称为分组或者包,也可以称为数据报(Datagram),而UDP是构建在网络层之上,面向用户使用的,所以就称为用户数据报(User Datagram)。
这么看UDP以源IP和Port为基础,向外进行多点调用,也就是进行广播。除此广播以外,UDP能干的,TCP全部能干,而且可靠,那要UDP干啥?原因在于,UDP协议短小,同时没有流量控制和拥塞控制,简单说就是不讲究,只管发送和接收,相对延迟小,比较适合实时流媒体,比如:webcam。现实是有些防火墙会禁用UDP协议,所以快这个好处也不见的那么好使。
TCP是面向连接的传输服务,叫面向连接而不是基于连接,就是站在网络传输的两端来说的,因为它们各自都向连接中发送或接收数据,感觉上好像和对端建立了一个现实存在的连接,但实际上并没有。使用TCP通信的双方会有连接建立的过程,那只不过是一种达成共识的手段,它需要双方系统内核(或者说协议栈程序)来维护这个共识,如果其中一方突然掉电关闭,对端的连接是不会关闭的,而是以为这个连接仍然存在。
面对这种意料之外的突然下线,依旧存活的一方还是可以向这个连接发送数据,只是没有响应,而操作系统内核会检测出发送数据的响应超时,进而采取关闭连接的行动。
RDT的设计与演化
TCP看起来很神奇,但在复杂的东西都是从简单的事物演进而来的,接下来就跟随本文来设计一款可靠数据传输协议。RDT(Reliable Data Transfer),即可靠数据传输,我们通过思考如何构建一个可靠的数据传输协议来理解TCP协议面对的问题,以及根据RDT的解法来思考TCP中那些不易理解的知识点。RDT协议是构建在网络层之上的,因此它支持分组交换的基本特性,同时它接收应用层数据,并按照要求进行传输。
我们自定义的RDT协议接收应用层传输的数据并完成传输,也就是应用层需要调用RDT提供的方法进行数据发送和接收,在这里假设两个方法对应上述操作:rdt_snd(Segment segment)和rdt_rcv(Packet packet)。对于rdt_snd方法而言,应用层需要创建好Segment报文对象,其中包括需要传输的字节数组,然后rdt_snd方法负责发送到对端。对于rdt_rcv方法而言,从网络层收到分组Packet后进行转换处理,将其转为Segment后,调用应用层的处理逻辑,这样就实现了数据响应。
RDT协议构建在网络层之上,发送时需要将Segment转换为Packet进行发送,接收时将收到Packet转为Segment进行应用回调。对网络层的发送和接收分别假设存在net_snd(Packet packet)和net_rcv(Packet packet)两个方法,至于它们和数据链路层的关系,RDT协议就不关心了,只知道Packet在传输时,需要传入来源和目标IP。
RDT协议的设计无法一蹴而就,需要经过逐步的假设和推演逐步完善,而假设是基于网络层的服务质量而来的,如果网络层能保证可靠,rdt_snd和rdt_rcv就直接调用网络层提供的方法就好了,但现实没有这么简单,不过我们还是一步一步来。在正式开始前,对于传输可靠性我们需要有一个标准,这样才好确定协议的目标以及效果,一般来说传输层服务的可靠性体现在:不出错、不丢失和不乱序这三点上,简单说就是不错、不丢和不乱。
RDT 1.0
假设网络层提供的通信服务是可靠的,也就是数据传输:
- 没有比特出错,即不错;
- 没有分组丢失,即不丢;
- 没有分组乱序,即不乱。
在这么靠谱的网络层面前,连神仙都会给它点个赞,我们RDT就能像Spring一样,啥都不干的包一层,至于苦力活么?交给网络层(Tomcat)干去,自己写,指不定多少bug。
RDT 1.0数据发送的调用关系,如下图所示:
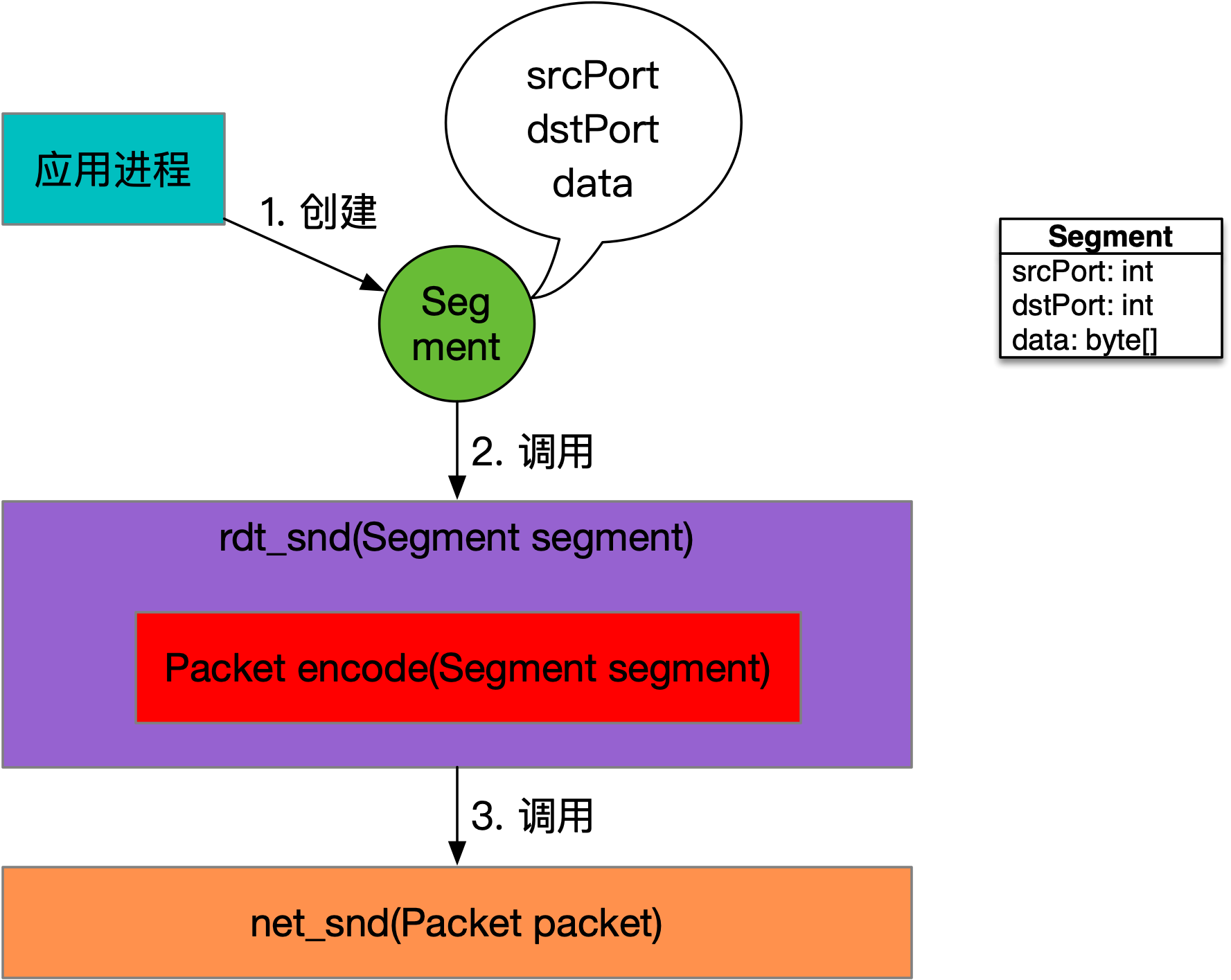
如上图所示,传输层需要提供进程到进程的通信解决方案,因此RDT协议要求:发送数据的应用进程需要给定一个标识,同时也需要给定对端应用进程一个标识。最合理的方式是进程ID,但是由于这个ID经常变动,所以就用一个命名空间来替代,叫:端口,一个整型就好。
发送方设置好Segment的srcPort和dstPort,也就是来源端口和目标端口后,就可以填充数据data进行发送了。rdt_snd方法的实现非常简单,只需要调用encode方法,将Segment转为Packet,然后调用网络层提供的net_snd方法即可。
RDT 1.0数据接收的调用关系,如下图所示:
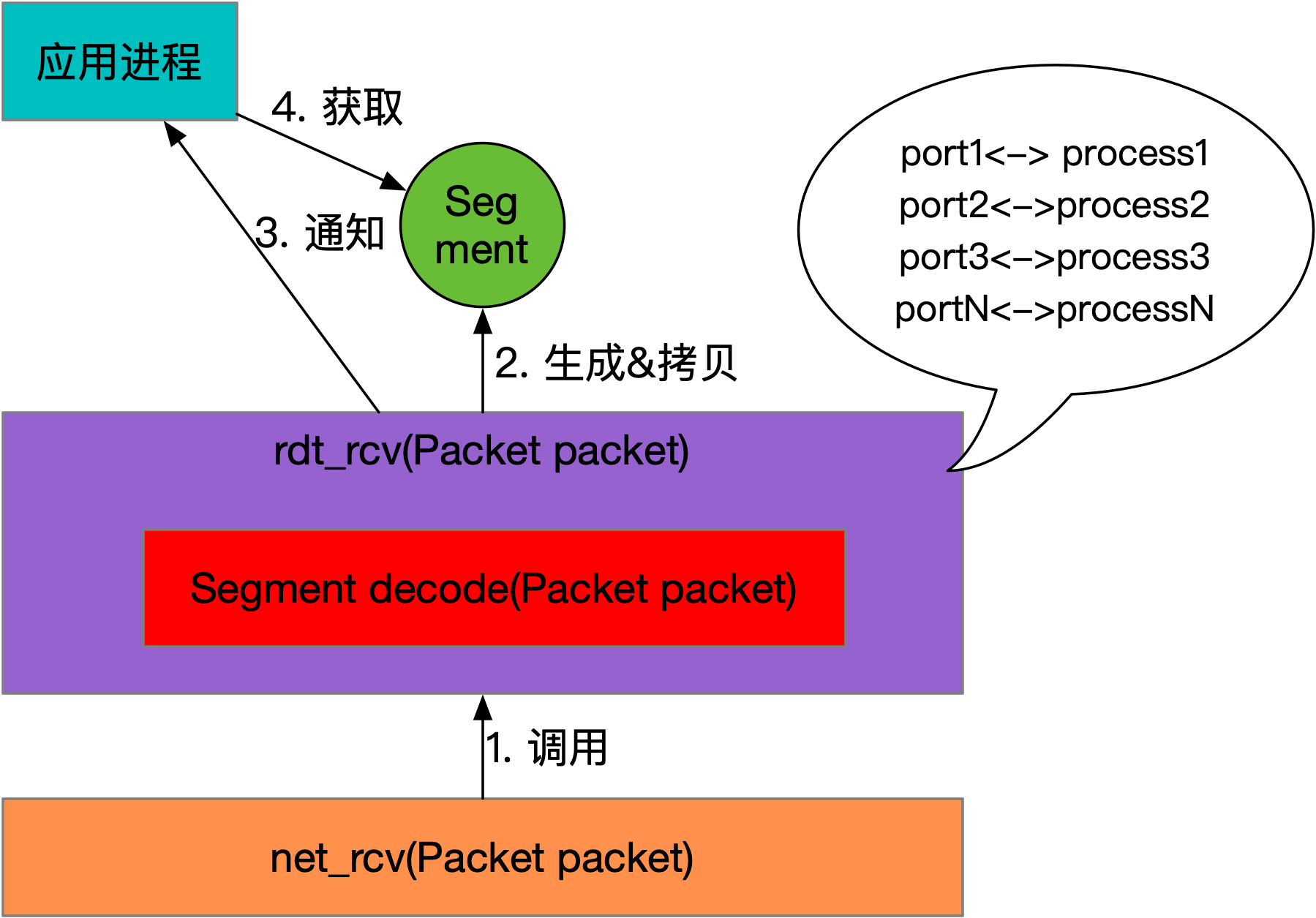
如上图所示,接收方从net_rcv方法收到Packet,然后调用rdt_rcv方法进行处理。rdt_rcv只需要调用decode方法,将Packet转换为Segment,随后可以根据Segment.dstPort来确认数据包是发给哪个应用进程的。协议栈程序查找确认进程后,将数据从内核拷贝到对应的进程空间中,由于用户进程阻塞在IO读取的操作上,接下来唤醒用户进程,使其从IO读取操作上拿到数据并返回即可。
RDT 1.0基于可靠的网路层,抽象出了端口这个概念,解决了进程到进程的通信。
RDT 2.0
接下来,我们逐步拆除网络层通信服务可靠传输的假设,目的是最终能够在不可靠传输的网络层上,构建出一个能够支持可靠传输的传输层协议。对于网络层的通信服务,假设变更为:
- 可能比特出错,即有错;
- 没有分组丢失,即不丢;
- 没有分组乱序,即不乱。
传输层接收到应用需要发送的字节数组,转换为Packet后进行发送,如果对端收到内容,字节数组中某些位由于传输时信号干扰导致解码后出现错误,这样传输层就不是可靠的了。
解决办法也比较简单,在发送字节数组之前,给Segment设置一个属性checkSum,一个整数,它可以通过两端都具备的一个摘要函数来生成,比如:int check_sum(byte[] payload)。这样对端收到字节数组后,使用check_sum函数计算后,同Segment中的checkSum值进行比对,通过比对摘要值就知道数据是否出错了。
接收方进行数据校验时没有出错还好,如果出现错误,就需要通知发送方进行重新发送,这样就需要设计一个应答Segment。如果只是错误了才回复显得太局限,那就干脆设计成两种应答Segment,一种是成功应答ACK,另一种是失败应答NACK,二者都继承于Segment。
RDT 2.0数据发送的调用关系,如下图所示:
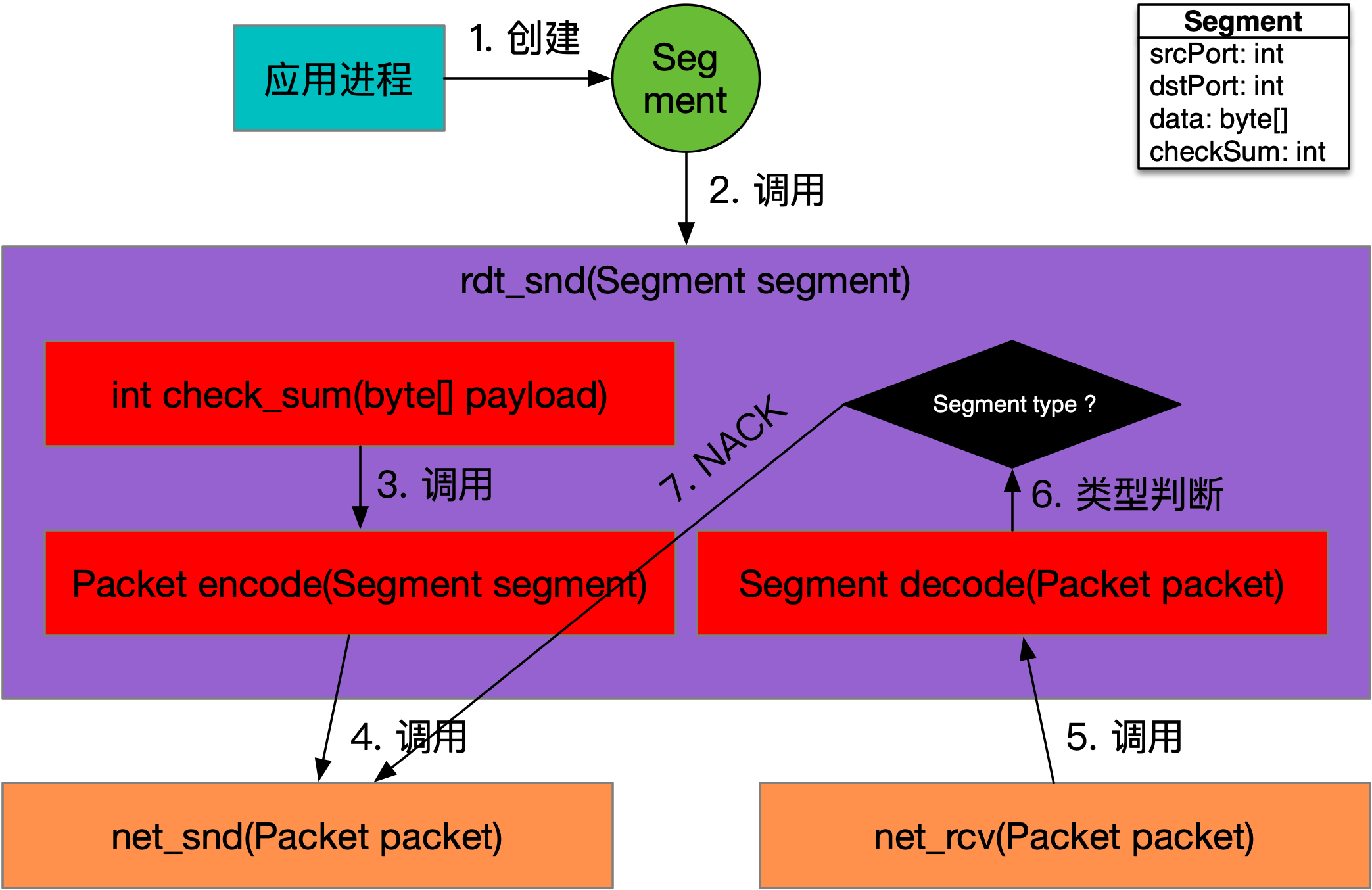
如上图所示,应用依旧调用rdt_snd方法发送数据,而该方法的实现有了改变。
首先,需要在发送数据之前调用check_sum方法计算出待发送字节数组的摘要checkSum,将其设置到Segment中。其次,将构造好的Segment转换为Packet,调用net_snd方法进行发送,发送后不能直接返回,还需要调用net_rcv方法,等待对端的响应。最后,如果响应Packet收到,将其转换为Segment,如果类型是ACK,则返回,发送成功;如果是NACK,则调用net_snd方法进行数据重发。
RDT 2.0数据接收的调用关系,如下图所示:
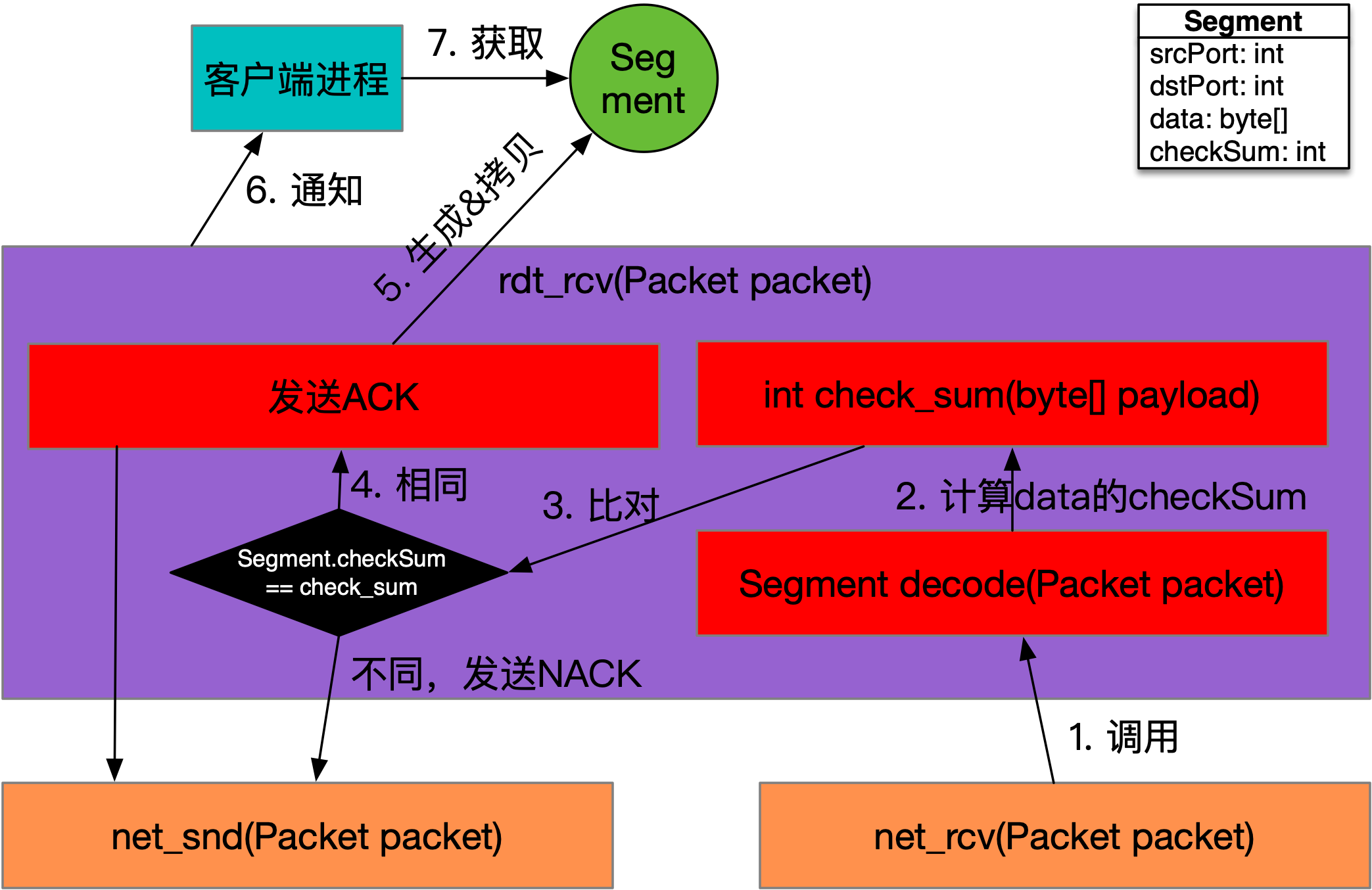
如上图所示,网络层收到分组Packet,将其传递给rdt_rcv方法,由传输层RDT来处理,由于checkSum和应答的出现,rdt_rcv实现会有所变化。
rdt_rcv依旧是将Packet转换为Segment,然后使用check_sum方法计算Segment.data的摘要,并与Segment.checkSum进行比对。如果相等,则调用net_snd方法,发送ACK应答,同时将Segment.data返回给应用进行处理,反之,发送NACK应答,等待发送方进行重传。
随着checkSum和应答机制的加入,在网络层传输可能出现比特错误的情况下,RDT 2.0依旧能够可靠工作,通过让发送端进行重传来承担起可靠性的责任。
RDT 2.1
RDT 2.0在发送字节出错的情况下,能够搞定可靠传输,不容易。接下来,我们再继续挖墙脚,对于网络层的通信服务,假设变更为:
- 可能比特出错,即有错;
- 可能分组丢失,即会丢;
- 没有分组乱序,即不乱。
RDT 2.0虽然具备纠错功能,但对于分组会丢的情况就无法处理了。应用层将需要传输的字节通过调用传输层的rdt_snd方法进行发送,如果传输中的Packet出现跨多个路由节点后丢失的情况,该如何应对呢?现实世界中,如果一方寄送包裹,另一方收包裹,接收方如何判断出有包裹漏掉了呢?答案是,给包裹编号。假设寄送包裹的一方会给包裹上贴一个面单编号,而且这个编号是自增的,那么接收方就可以根据这个编号来判断出有没有包裹漏掉,比如:接收方收到的包裹编号是{1, 3,4},那么就代表{2}号包裹丢失了,这时就要通知发送方检查一下{2}号包裹的寄送情况。
发送时有编号,应答确认回复时能指出编号,因此需要在Segment上增加两个编号字段,类型可以是整型,一个叫:sequence,代表报文Segment的发送编号,另一个叫:ack,代表接收方确认收到的编号。假设发送端发送Segment.sequence为3的Segment,接收端收到的上一个Segment,其sequence为1,则接收端收到3号Segment后,就认为2号Segment丢失了。此时,最简单的做法是直接丢弃3号Segment,同时发送NACK.ack为2的应答。
发送方收到NACK,同时ack编号为2,此时就会将2号Segment进行重发。
RDT 2.1数据发送的调用关系,如下图所示:
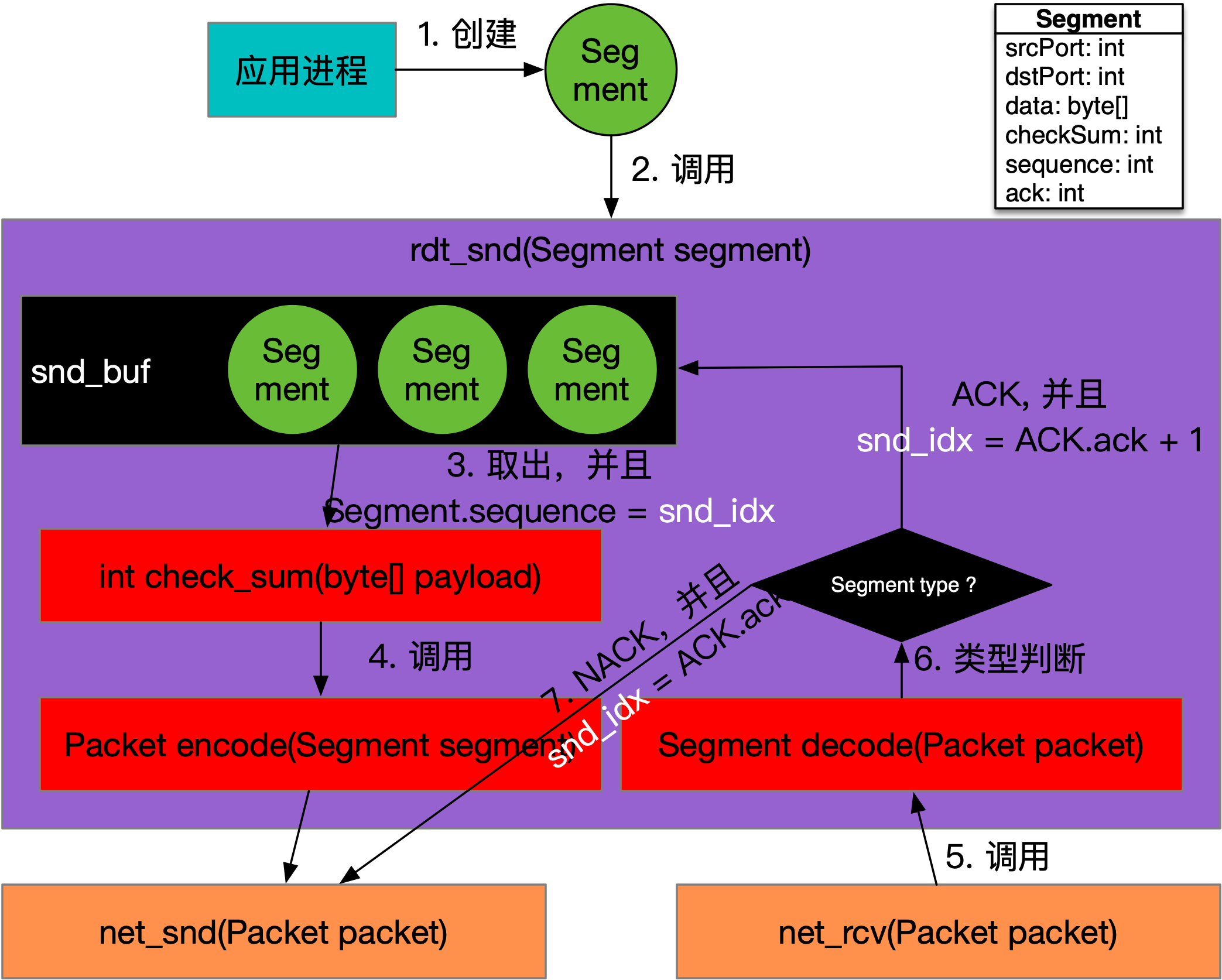
如上图所示,rdt_snd方法变得更加复杂了,它会将需要发送的Segment先编号,然后放置到缓冲区snd_buf中。这个编号就好像数组的下标一样,当发送时,从Segment数组,也就是snd_buf中,依据snd_idx取出一个Segment进行发送,接着执行net_rcv方法处理应答。
如果响应是ACK,则将ACK.ack + 1作为发送游标snd_idx的值,即snd_idx = ACK.ack + 1,然后继续发送下一个Segment。如果响应是NACK,则将NACK.ack作为发送游标snd_idx的值,也就是snd_idx = NACK.ack,相当于要进行重发了。
发送方会根据ACK或者NACK中的ack编号来调整发送的Segment,由于发送和接收是对称的,所以从两端来看,如果发送端的Segment是src,接收端收到的Segment是dst,那么数据传输的可靠性就需要让以下两个等式成立,即:src.sequence == dst.ack和src.ack == dst.sequence。
为什么会有
src.ack == dst.sequence,因为传输层是双向的,此时接收端,彼时发送端。
RDT 2.1数据接收的调用关系,如下图所示:
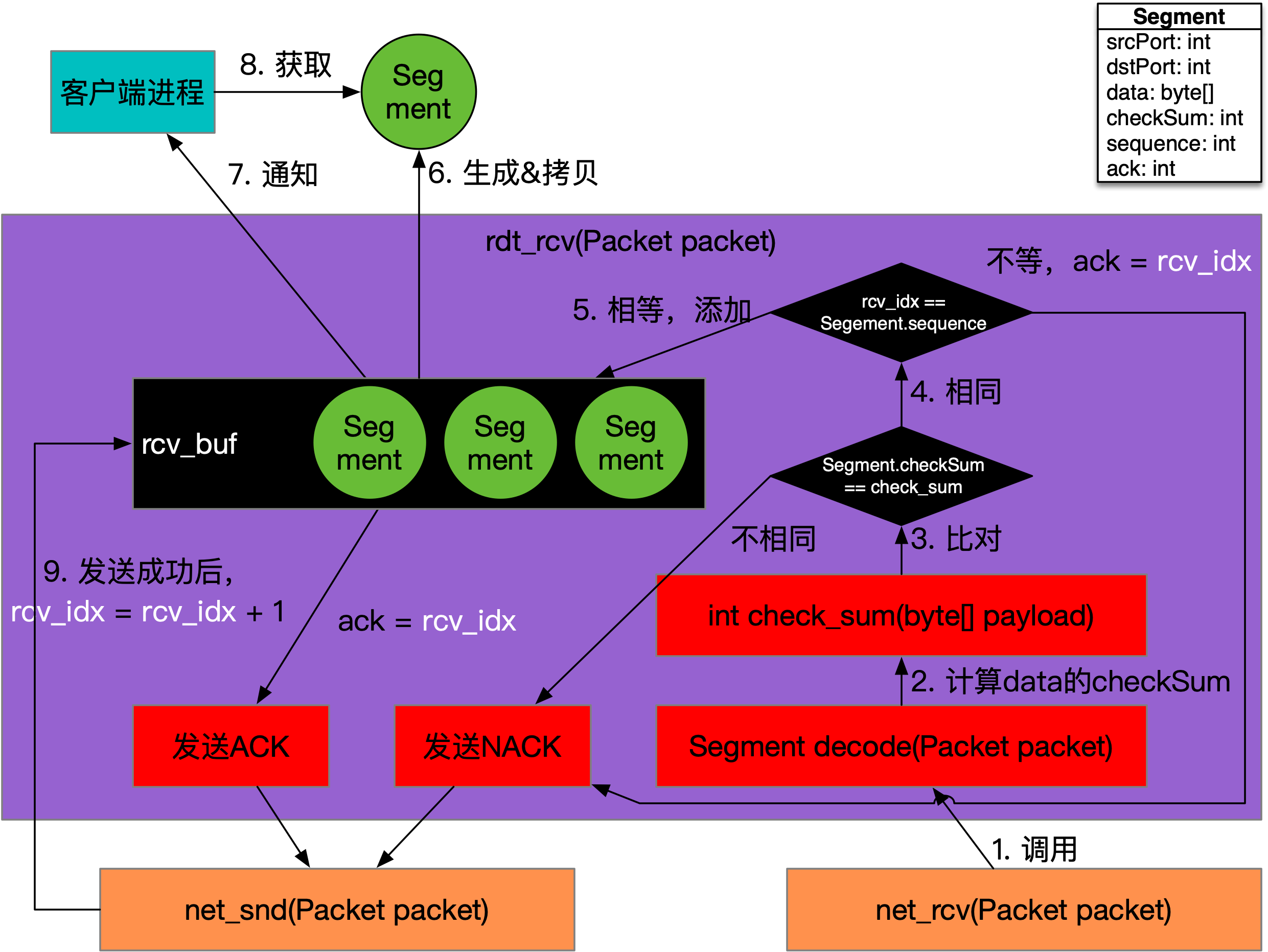
如上图所示,rdt_rcv方法也需要准备一个缓冲区rcv_buf,顺序的将接收到的Packet转换为Segment后,根据接收游标放置到缓冲区数组中。
接收方需要定义一个期望接收的游标,称为rcv_idx,然后根据它与Segment.sequence进行比对,在check_sum方法比对的基础上,还需要看一下sequence是否是自己想要的。如果rcv_idx == Segment.sequence,则将Segment放置到数组中,并将数据返回给应用程序,同时调用net_snd方法发送ACK,其中ack设置为rcv_idx,发送成功后,将rcv_idx更新为rcv_idx + 1,代表接收方想收下一个Segment了。如果rcv_idx != Segment.sequence,则代表rcv_idx编号的数据包没有收到,只能丢弃掉当前处理的Segment,同时调用net_snd方法,发送NACK,其中ack设置为rcv_idx。
可以看到,接收方知道自己的目标序号,回复ACK或者NACK给发送方,如果收到的Segment.sequence为目标序号,则表明之前的数据接收都是成功的。从发送方的角度看,snd_idx指的是发送Segment的预期,而一旦接收到的ack值与之相等,则代表对端成功接收到了数据,所以通信的两端都对收到的数据sequence或者ack有预期,而这个预期就是维护在各端内存中的状态(比如:snd_idx或者rcv_idx)。
RDT 2.2
RDT 2.1已经相当完善了,在一定程度上能够可靠的工作,不过代价就是太复杂了,比如:接收方需要回复ACK或者NACK,而发送方也需要处理ACK和NACK。到这个阶段需要做一些协议重构,让它变得统一和简单些,在假设不变,即网络传输有错、会丢但不乱的前提下,看看该如何优化现有的RDT协议。
从ACK和NACK下手,通过观察传输层的工作,其实就是一个按编号搬运数据的过程。NACK实际上可以被ACK所统一,也就是说:ACK(0) == NACK(1),NACK表示需要重传{1}号Segment等同于ACK表示接收方已经收到了{0}号数据包,因为编号自增是双方的共识。
ACK和NACK的对应关系,如下图所示:
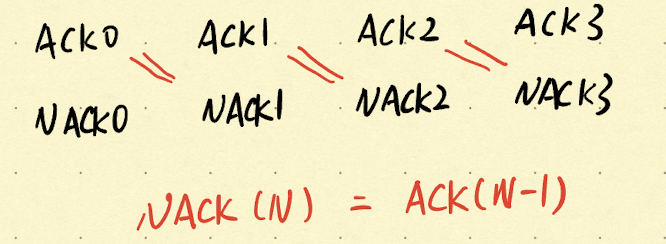
如上图所示,可以提炼出二者之间的关系,即:NACK(N) = ACK(N - 1),在此基础上,可以尝试对RDT 2.1进行优化。另外一点,既然Segment带有ack属性,那么完全可以不使用Segment的子类ACK,直接基于Segment就好了。
RDT 2.2数据发送的调用关系,如下图所示:
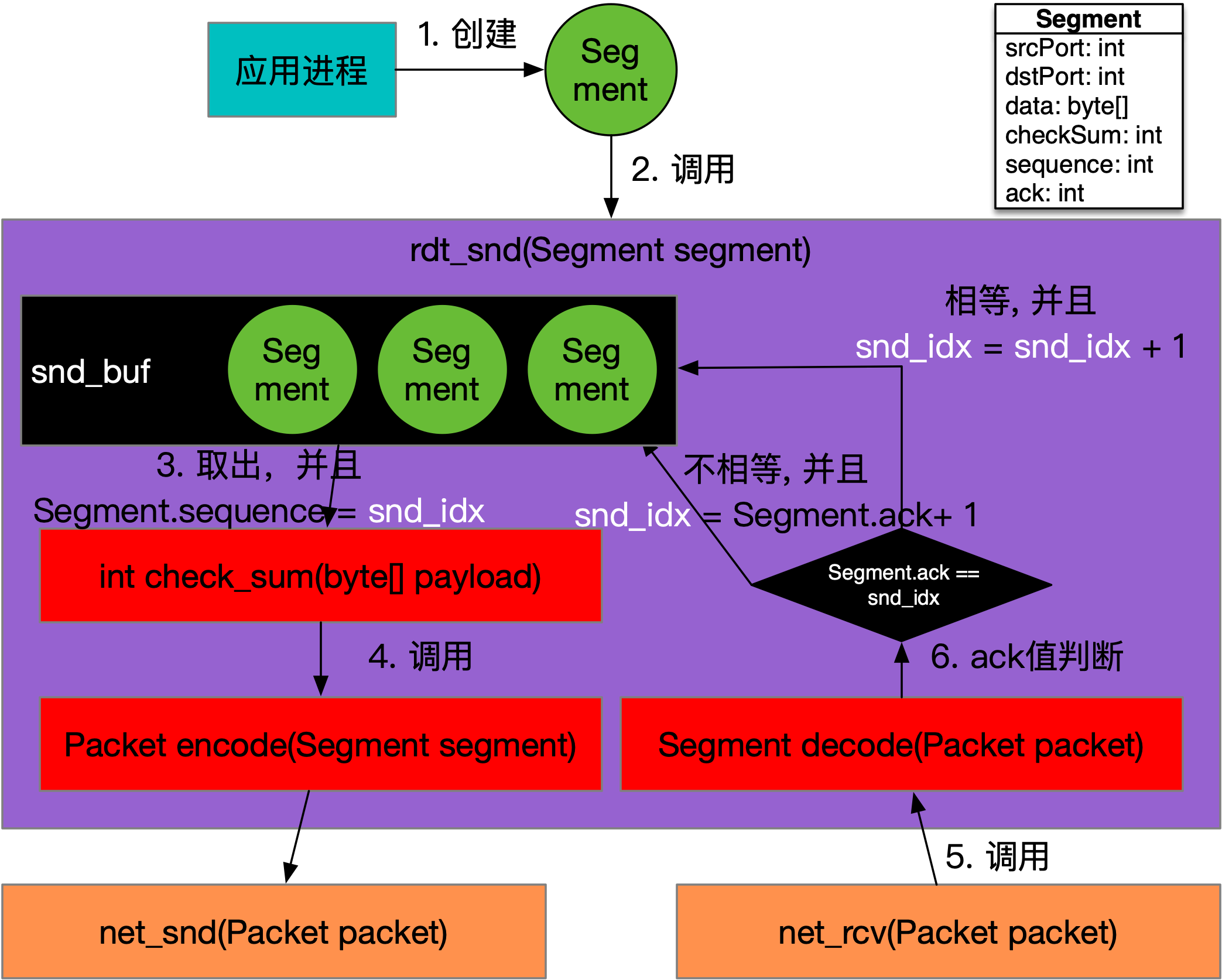
如上图所示,rdt_snd方法对于数据发送的行为不变,而是调用net_rcv方法收到Packet后的处理逻辑有所不同。将Packet转换为Segment后,如果该Segment.ack == snd_idx,则代表发送的数据被确认,没有丢失;如果该编号不等于snd_idx,则重发Segment.ack + 1的Segment。
举个例子,如果发送的Segment.sequence = 20的数据包到了对端,接下来应该发送编号为{21}的数据包,但是发送端却收到了Segment.ack = 19的回执Segment,它代表接收方收到了[0, 19]的数据包,这里我们假设sequence从0开始。如果接收方收到了{19}及其之前的数据包,那么{20}号数据包就是没有收到,发送方就需要发送第{20}(19 + 1 )个Segment,这表示在重发了。
RDT 2.2数据接收的调用关系,如下图所示:
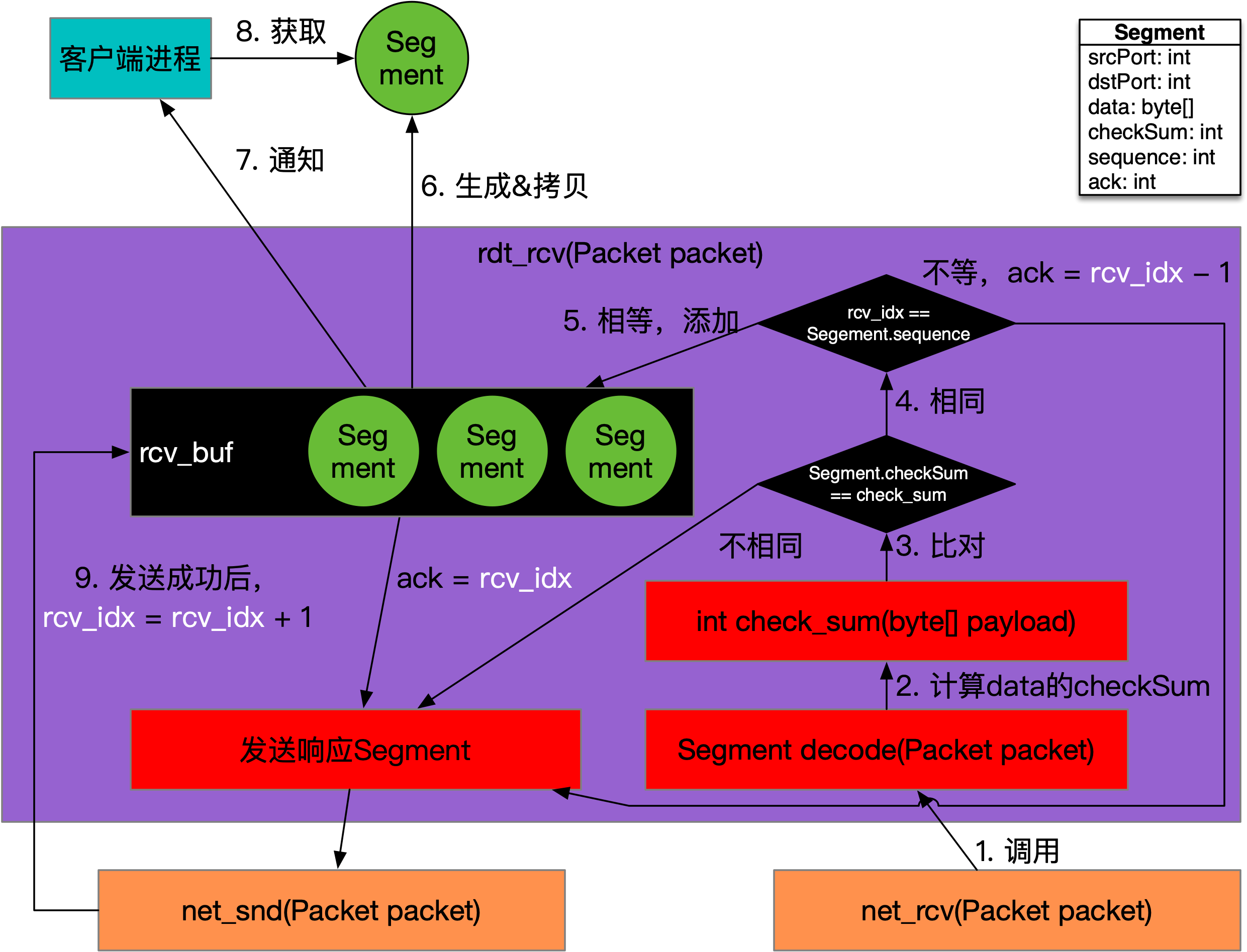
如上图所示,rdt_rcv方法在处理Segment时,只需要关注Segment.sequence和rcv_idx的关系,如果符合期望,即Segment.sequence == rcv_idx,则将Segment添加到rcv_buf,随后交给应用进程,否则做重传处理。响应的结果不用区分ACK或NACK,而统一用Segment的形式发回,只是在ack的设置上有所不同。
如果请求Segment.sequence == rcv_idx,表示符合期望,则响应的Segment.ack会设置为rcv_idx,同时rcv_idx自增。如果不符合期望,则响应的Segment.ack会设置为rcv_idx - 1,代表收到了编号小于等于rcv_idx - 1的所有Segment,期望对端重发rcv_idx的Segment。
从响应Segment看,无论收到Segment.sequence是否符合期望,响应Segment.ack始终表示接收端已经收到的(最大)编号,核心思想就是:作为接收方,我已经成功收到第几个数据包。
RDT 3.0
RDT 2.2在字节发送出错,且发送分组可能丢失的情况下,能够完成可靠传输,并且将发送和响应的数据结构做到了统一。接下来对于网络层的通信服务,假设变更为:
- 可能比特出错,即有错;
- 可能分组丢失,即会丢;
- 存在分组乱序,即会乱。
如何在一个有错、会丢和会乱的网络层通信服务基础上,支持可靠的数据传输?RDT 2.2其实在一定程度下是可以做到的,只需要假设网络层的消息传递是完全同步的,也就是每个数据包到对端后,对端响应发回来,然后才可以发送下一个数据包,其本质就是一个同步的半双工网络。
如果只是两点传输,同步半双工网络慢也就算了,但是在分组交换网络中,如果完全同步,就会造成大量的带宽容量浪费。因为发送后同步等待响应的效率太低,如下图所示:
如上图所示,发送方和接收方之间分组交换设备的带宽只有发送传播和应答传播两段时间在服务,其他的时候均是空闲的,网络容量无法跑满。提升网络带宽的利用率,最直接的做法就是让发送方做到批量发送,异步接收响应,这样就可以尽可能的跑满带宽。
如果发送方一次发送多个数据包,每个Segment的sequence可以做到自增,但接收方响应的ack该如何判定?与此同时,接收方如果由于网络延迟导致应答的很慢,发送方该如何确保数据一定会重传?发送方如果一次发送多个数据包,接收方如果只接收一个,那么效率也会变低,如果同时接收多个,超出了接收缓存rcv_buf的上限该怎么办?
分组乱序需要做到:发送方异步多发,接收方异步多收,这样的异步全双工网络实现起来就很有难度了。如果是全同步的网络,它会非常符合人类直观思考,但其效能也是非常低的。要建立异步全双工网络,这么多问题需要逐一解决。
首先,对于N个发送的Segment,接收方回复不必是对等的N个响应Segment,而是M个Segment,其中M <= N,也就是用更少的响应来支持传输会话。举个例子,如果发送方一个批次发了[1, N]共N个Segment,由于接收方收到这些数据包有先后,当先收到完整的[0, X]后,就回复响应Segment,其中Segment.ack = X,代表前X个数据包收到了,再等到所有数据包都收到后,最后回复对第N个Segment的确认。这样只需要两三个响应就让发送方和接收方达成了共识。每次发回的响应,从接收方发出的一瞬,ack编号始终是递增的,如果每收到一个包就发送对应的响应,那么ack编号在发送方看来,由于乱序收到响应,ack编号就看来就显得飘忽不定了。
其次,顺着这个思路,站在发送方的角度看,收到的ack就是跳跃的,那么如何能够确定发送的Segment中有哪一个被漏掉了?对于重传的确保,需要对Segment发送设置超时时间,这样可以保证数据一定会进行重传发送。当一个Segment进行发送后,会设置一个计时器,如果在一段时间内,没有收到超过(或等于)它编号的响应,就发起重传。有了超时重传的兜底,发送方就更具备容错和防丢失的能力了。
最后,超出接收缓存上限的问题。该问题的本质是发送方不断的发送Segment,而由于接收方处理的速度较慢,导致接收缓存rcv_buf被占满。处理的方式其实很简单,如果发现rcv_buf满,直接丢弃即可,因为增加了发送方的超时重试,所以不用担心数据会丢。这么做简单粗暴,但是丢弃的网络流量还是浪费了,如果能够告知发送方,接收方的rcv_buf还能容纳多少Segment,那就最好了,因为发送方可以根据接收方rcv_buf的大小来调整发送数据包的节奏。
可以尝试在Segment中定义一个接收窗口的属性,叫:rwnd,当每次响应的时候,就将当前可用的缓存大小设置到该属性,由响应Segment带回。发送端收到响应Segment后,不仅要做数据完整性检验,也需要看一下ack做好重发处理,同时还要根据rwnd属性来调整一下接下来发送的数据量。
通过不对等的发送和应答,增大了RDT的吞吐量,同时超时机制的引入,使得不对等发送和应答的基础上,也能保证重传,rwnd的引入,接收方无形中可以影响到发送方的发送速率。如果我们离远一点观察RDT 3.0,你会发现发送方和接收方通过Segment的属性,以及维护在两端各自的缓存和游标,相互牵引,相互制约,将数据从发送方完整的搬到接收方。
当前的RDT 3.0协议,已经和TCP协议非常像了,或者说它已经是一个原始版的TCP协议了。
RDT 3.0数据发送的调用关系,如下图所示:
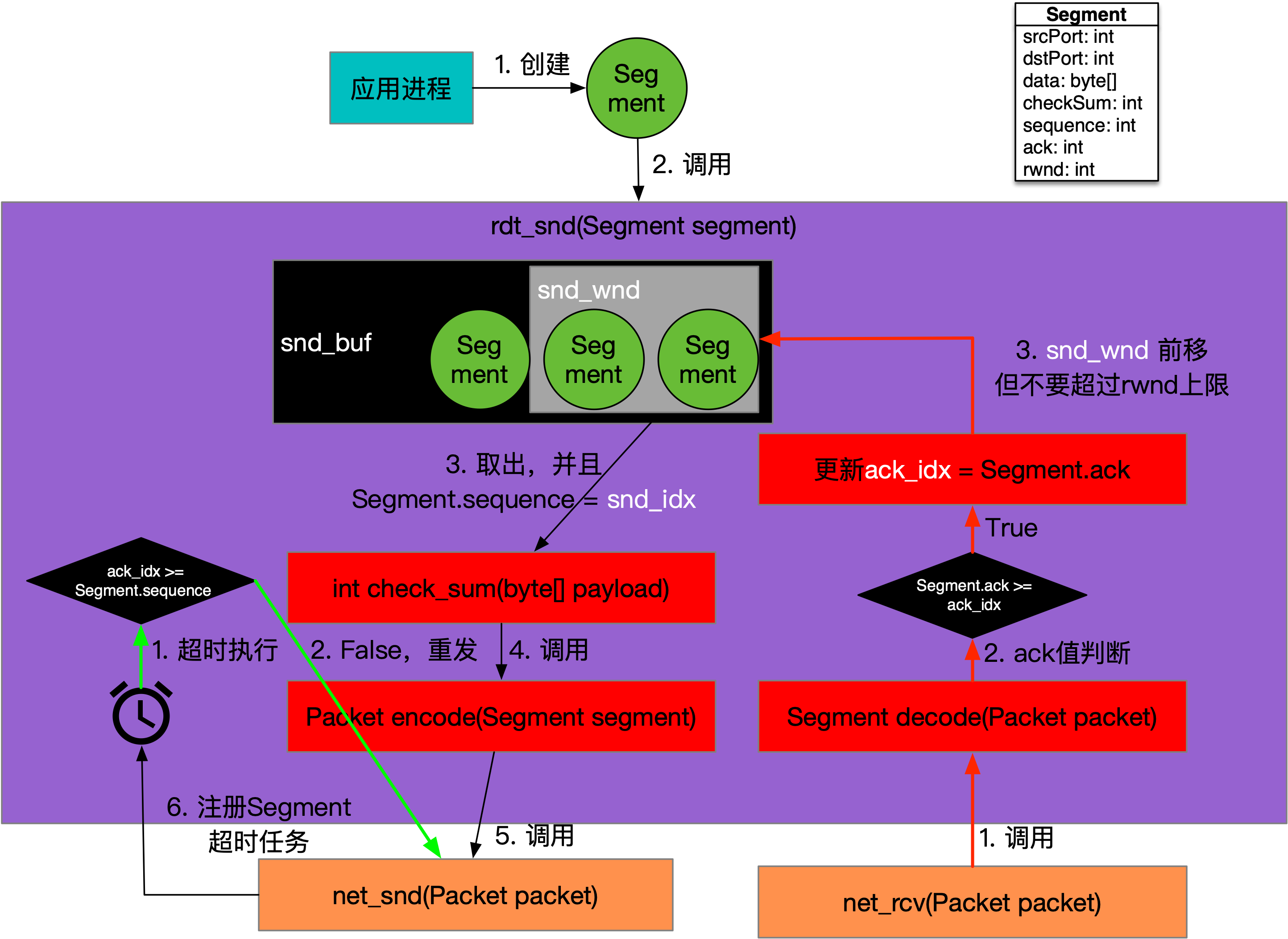
如上图所示,其中黑色线路为发送流程,红色线路为确认流程,而绿色线路为超时流程,这些流程分别运行在不同的进程中。应用层调用rdt_snd方法后,只是将Segment存放到发送缓存snd_buf中,而缓存中每次会选定一个固定的数量进行发送,可以称为发送窗口snd_wnd,超出snd_wnd的Segment暂时不发。snd_idx指向snd_window的起始位置,然后顺序设置Segment.sequence并调用net_snd方法,将Packet发送到网络,当snd_idx到达snd_wnd的结束位置时停止。
由于net_snd方法是异步执行,所以引入了ack_idx来表示发送方收到的ack编号,它和snd_idx一样,会一直递增,只是ack_idx的设置来自于对端的应答响应,而不是像snd_idx那样的主动自增。发送每个Segment时,还会注册对应的定时任务,每隔几秒会检测当前任务中Segment的sequence和ack_idx之间的关系,如果ack_idx >= sequence,则返回,否则定时任务会重新调用net_snd方法重传当前定时任务负责的Segment。
net_rcv方法接收来自对端的响应,如果响应Segment.ack >= ack_idx,则更新ack_idx为响应Segment.ack,代表目前已经有ack及其之前的Segment都被收到。收到响应的一刻,snd_idx - ack_idx < snd_wnd,这代表在确认路途上的Segment数量已经小于发送窗口snd_wnd的长度了,此时snd_wnd开始向前移动,snd_idx可以突破旧有的限制,继续将向前移动多出来的Segment发送到网络中。
可以看到基于缓存和超时rdt_snd方法已经变得很复杂了,但是它的效能和适应性也得以提升,发送的频度受限于接收的能力,RDT 3.0已经建立起了具备反压特性的传输机制。
RDT 3.0数据接收的调用关系,如下图所示:
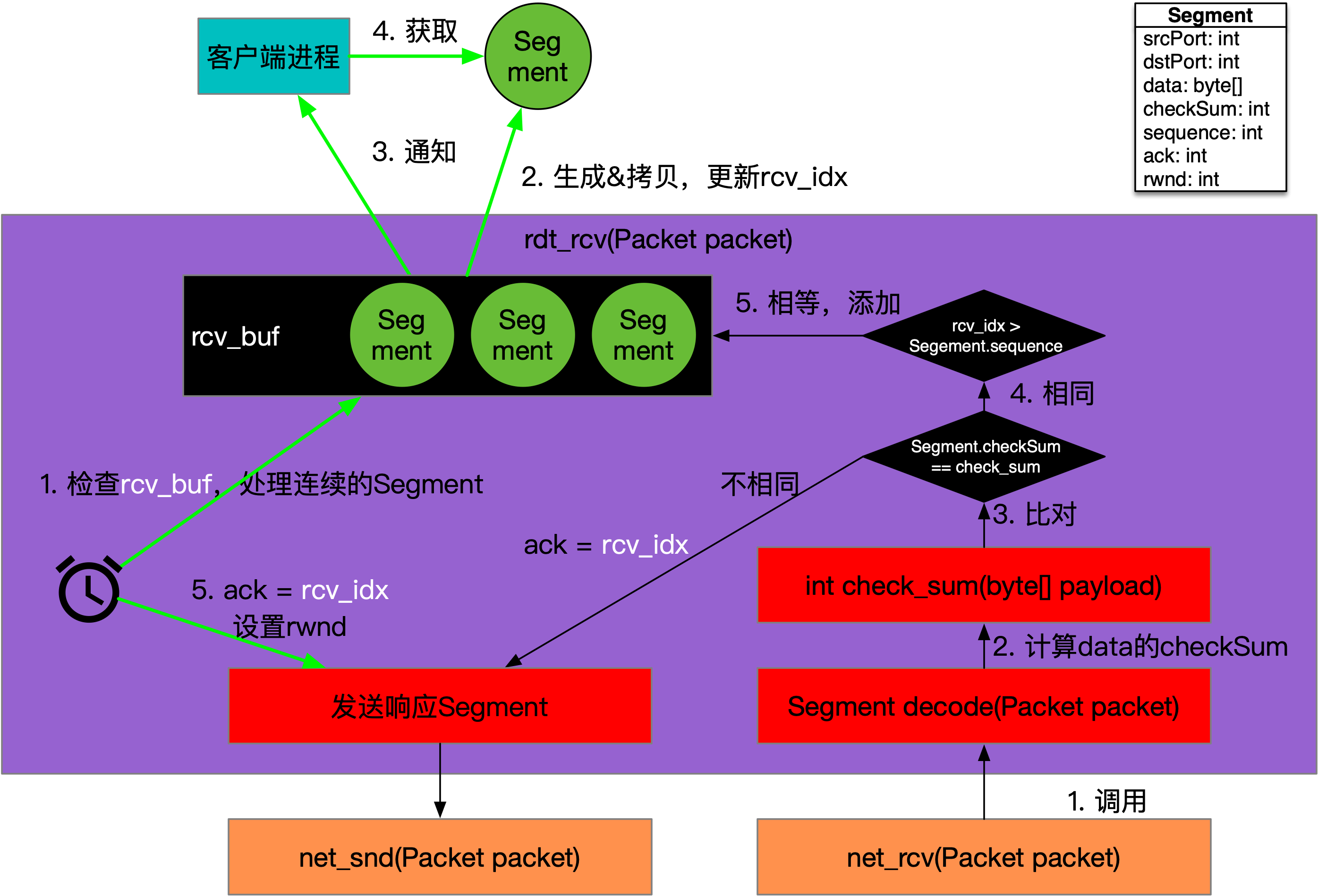
如上图所示,其中黑色线路为接收流程,而绿色线路为定时触发流程,这些流程分别运行在不同的进程中。rdt_rcv方法不是在单个的处理Segment,对端发送窗口内的Segment会并发到达。rcv_idx指向接收缓存rcv_buf中的起始位置,当接收到Segment后,如果sequence < rcv_idx,则丢弃并返回,否则将Segment存入到rcv_buf中对应的编号处。
接收方会周期检查rcv_buf,如果从rcv_idx开始有连续若干个Segment都收到了,则将连续的几个Segment中的data数据交给应用进程,并前移rcv_idx,同时发送响应Segment,其中ack等于rcv_idx,表示rcv_idx之前的数据包都收到了。
响应Segment发送到发送方,又会触发发送方的snd_window前移,进而发送后续的数据。
RDT 3.1
RDT 3.0在一个有错、会丢和会乱的网络层基础上,不仅建立起了可靠的传输服务,还支持并行发送以及乱序接收,极大的提升了网络的利用率。RDT 3.0要求在两端保持一些状态,比如:rcv_idx、snd_idx和rcv_buf等,这些状态是服务于两端进程的,所以它们需要基于IP和端口被单独维护,如下图所示:
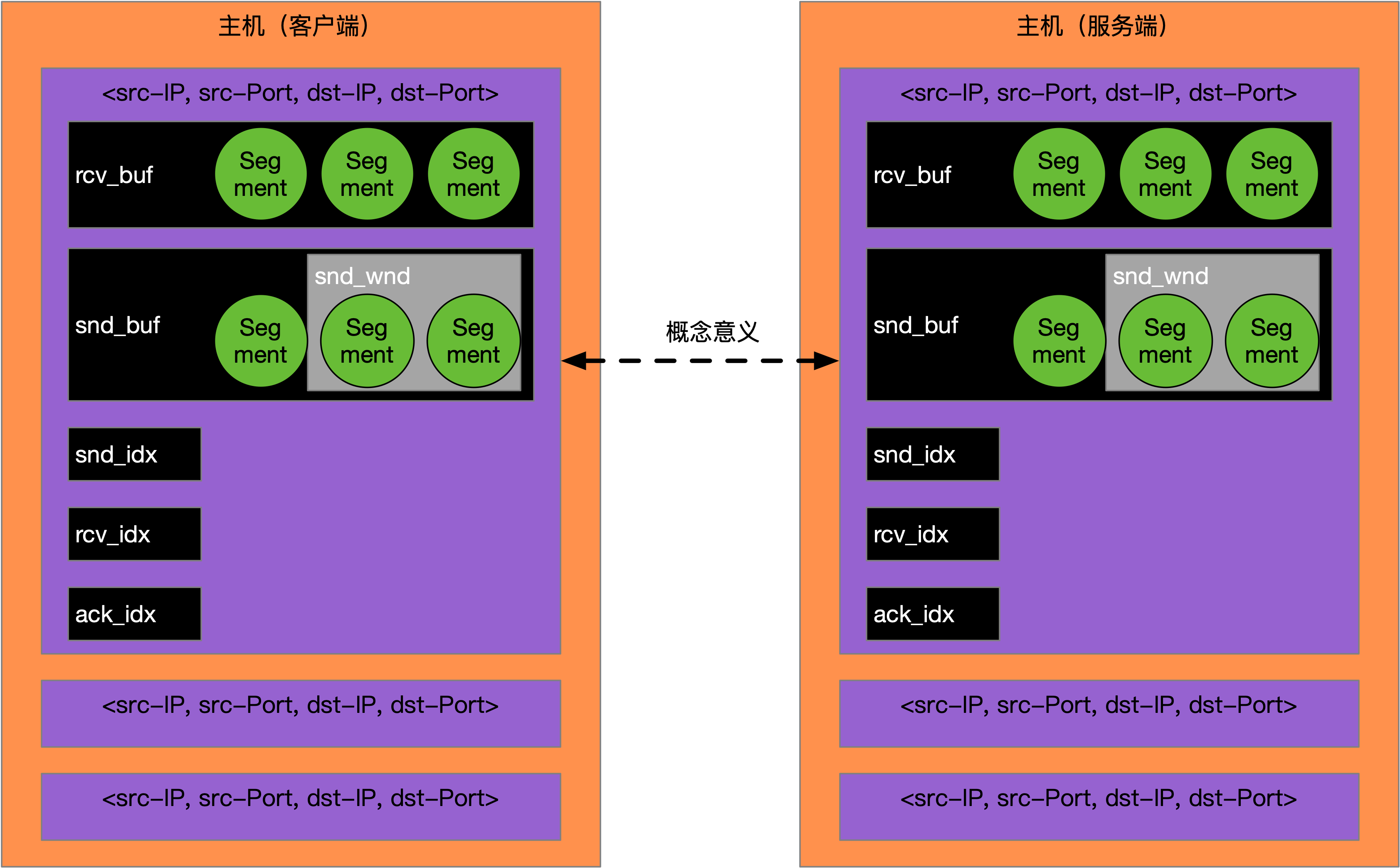
如上图所示,以发送端为例,会以<src-IP, src-Port, dst-IP, dst-Port>为KEY,开辟独立的通信属性,包括:rcv_idx、snd_idx、rcv_buf、ack_idx、snd_buf和snd_window,其中src是发送方,dst是接收方。虽然是发送端,但是也会分配rcv_idx和rcv_buf,原因是发送端不仅发送数据,也会接收对端的响应数据,传输层是全双工的。
发送端发送数据后,如果接收方响应数据的Segment很多,超过了发送端的rcv_buf限制,就会导致无效的重传。同时发送端的snd_idx起始值也需要给到接收端,这样方便接收端可以以此来确定自己的rcv_idx,所以RDT协议还可以增加一个控制数据包的概念,代表这个Segment中的数据是为了设置对端的通信属性。
可以使用一个整型,按照二进制位的方式来表示Segment的特性,比如4位二进制:0001,第一位为真表示该Segment是为了建立连接,接收方可以用Segment中的sequence属性来初始化自己的rcv_idx;0010,第二位为真表示该Segment的ack属性有效,可以用Segment中的ack属性来更新ack_idx;0100,第三位为真表示该Segment是为了断开连接,接收方收到该Segment代表它是发送方最后一个包含数据的Segment,同时也可以准备回收分配的通信属性了。
该整型定义为sign,这样升级为3.1的RDT就比3.0显得更加体系化了,以连接建立过程为例,如下图所示:
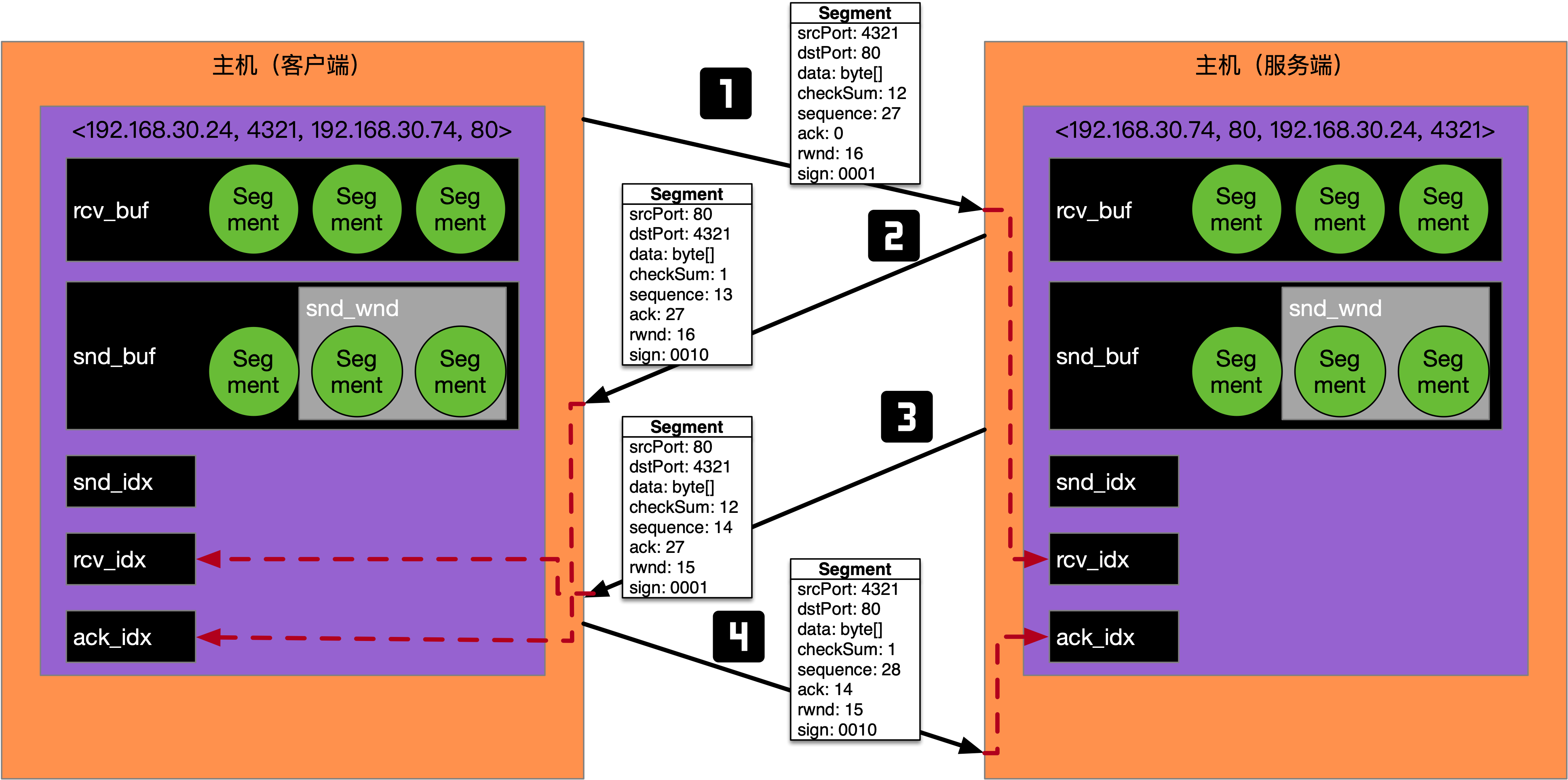
如上图所示,发送端发起一次连接建立操作,接收端也要进行一次连接建立操作,这样两端就完成了通信属性的交换,双方对于snd_idx,rcv_idx、ack_idx以及rcv_buf等有了共识。
由于sign可以合并,所以可以尝试将第二步接收端的响应和连接建立操作(第2步和第3步)进行合并,也就是Segment.sign = 0011,而Segment.sequence=13, Segment.ack=27,也就是只需要三次传输就能达成共识了。RDT 3.1可以说与TCP协议非常接近了,但是它还是局限在发送和接收两端,没有将两端之间的网络考虑在内,没有考虑网络拥塞的问题,但是它对于理解TCP协议是很有帮助的。