StampedLock的实现分析
接下来分析StampedLock的实现,主要包括:状态与(同步队列运行时)结构设计、写锁的获取与释放以及读锁的获取与释放。

状态与结构设计
StampedLock没有选择使用AQS来实现,原因是它对状态和同步队列的实现有不同需求。首先看状态,StampedLock需要状态能够体现出版本的概念,随着写锁的获取与释放,状态会不断的自增,而自增的状态能够反映出锁的历史状况。如果状态能够像数据库表中的主键一样提供唯一约束的能力,那么该状态就可以作为快照返回给获取锁的使用者,而这个快照,也就是邮戳,可以在后续同当前状态进行比对,以此来判断数据是否发生了更新。相比之下,AQS的状态反映的是任意时刻锁的占用情况,不具备版本的概念,因此StampedLock的状态需要全新设计。接着是同步队列的实现,AQS将同步队列中的节点出入队以及运作方式做了高度的抽象,这种使用模版方法模式的好处在于扩展成本较低,但是面对新场景却力不从心。虽然在程序运行在多处理器环境下,但并发冲突却不是常态,以获取锁为例,适当的自旋重试要优于一旦无法获取锁就立刻进入阻塞状态,AQS的实现与后者相似,它会导致过多的上下文切换,而选择前者的StampedLock就需要重新实现同步队列。
StampedLock使用了名为state的long类型成员变量来维护锁状态,其中低7位表示读,第8位表示写,其他高位表示版本,划分方式如下图所示:
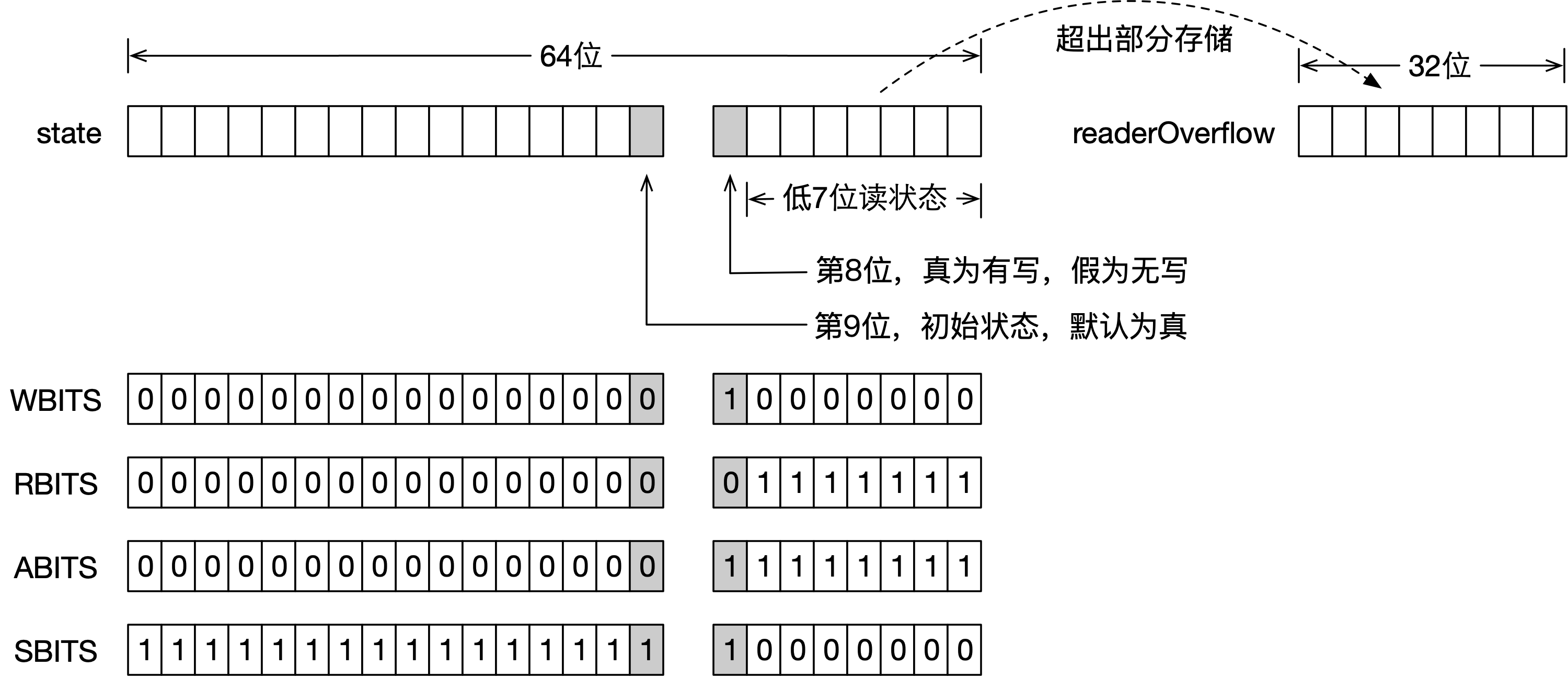
如上图所示,state实际仅使用低8位用于存储当前锁的状态,第8位如果是真(也就是1)表示存在写,反之不存在写。写锁具有排他性,使用一个位来表示,理论是足够的,但读锁具有共享性,需要使用一个数来保存状态。多个线程获取到读锁时,会增加低7位的数,而释放读锁时,也会相应的减少它,但二进制的7位最大仅能描述127,所以一旦超过范围,StampedLock会使用一个名为readerOverflow的int类型成员变量来保存“溢出”的读状态。
StampedLock仅用一位来表示写状态,就不能像AQS实现的读写锁那样,用一个16位的数来描述写被获取了多少次,从这里就可以看出该锁不支持重入的原因。如果写锁被获取,第8位会被置为1,但写锁的释放不是简单的将第8位取反,而是将state加上WBITS,这样操作,不仅可以将第8位置为0,还可以产生进位,影响到高56位,让高56位如同一个自增的版本一样,每次写锁的获取与释放,都会使得(数据)版本变得不同。如果不同线程看到的锁版本是一致的,那么它们本地所保存受到锁保护的数据也应该是相同的,这也就是乐观读锁运行的基础。
StampedLock实际使用包含了写操作位的高57位作为锁的版本。
StampedLock定义了若干long类型的常量,比如:描述写操作位为真的WBITS,state能够描述的最大读状态RBITS等,这些常量与状态进行表达式运算可以实现一些锁相关的语义,比如:判断锁是否存在读等。主要语义与表达式描述如下表所示:
| 语义 | 表达式 | 描述 |
|---|---|---|
| 是否存在读 | state & RBITS > 0 |
为真代表存在读 |
| 是否存在写 | state & WBITS != 0 |
为真代表存在写 |
| 验证邮戳(或版本) | (stamp & SBITS) == (state & SBITS) |
stamp为指定的邮戳,验证邮戳会比对stamp和state的高57位 |
| 是否没有读写 | state & ABITS == 0 |
为真代表没有读写 |
状态能够表示锁的读写情况,而等待获取锁的读写请求如何排队,就需要同步队列来解决。StampedLock自定义了同步队列,该队列由自定义节点(WNode)组成,该节点比AQS中的节点复杂一些,其成员变量与描述如下表所示:
| 字段名称 | 字段类型 | 描述 |
|---|---|---|
prev |
WNode |
节点的前驱 |
next |
WNode |
节点的后继 |
cowait |
WNode |
读链表,实际是栈 |
thread |
Thread |
等待获取锁的线程 |
status |
int |
节点的状态0,默认1,取消-1,等待 |
mode |
int |
节点的类型0,读1,写 |
WNode通过prev和next组成双向链表,而cowait会将等待获取锁的读请求以栈的形式进行分组排队。接下来用一个例子来说明队列是如何运作的,假设有5个线程(名称分别为:A、B、C、D和E)顺序获取StampedLock,其中线程A和E获取写锁,而其他3个线程获取读锁,这些线程都只是获取锁而不释放锁,因此只有线程A可以获取到写锁,其他线程都会被阻塞。当线程E尝试获取写锁后,同步队列的节点组成如下图所示:
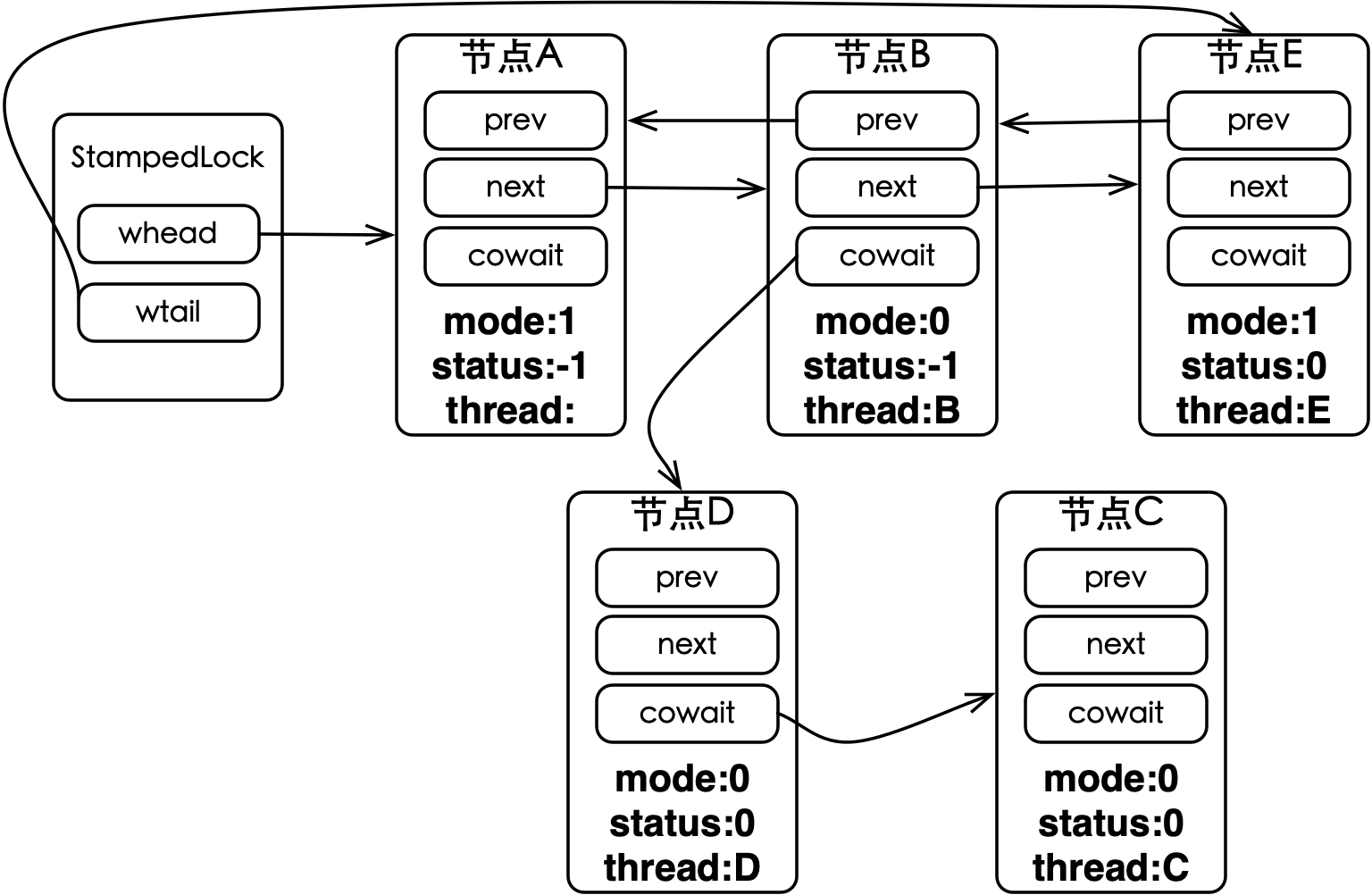
如上图所示,StampedLock通过whead和wtail分别指向同步队列的头尾节点。节点A是首节点,它是由第一个未获取到锁而被阻塞的线程所创建的,也就是线程B,该节点的类型是写,状态为等待。节点E是尾节点,线程E由于未获取到写锁,从而创建该节点并加入到队列中,节点类型为写,而状态为默认。节点状态的修改,是由后继节点在获取锁的过程中完成的,因为没有第6个线程获取锁,所以节点E的状态是默认,而非等待,获取锁的过程会在后续章节中详细介绍。
可以看到,同步队列的主队列是横向的节点A、B和E,而在节点B出现了纵向的子队列,原因是StampedLock将被阻塞的连续读请求进行了分组排队。节点B先进入同步队列,随后读类型的节点C会挂在前者cowait引用下,形成节点B至C的一条纵向队列。线程D由于未能获得读锁,也会创建节点并加入到了同步队列,此时尾节点是节点B,StampedLock选择将节点D入栈,形成顺序为节点B、D和C的栈。为什么纵向队列使用栈来实现,而不是链表呢?原因在于读类型的节点新增只需要由读类型的尾节点发起即可,这样做既省时间又省空间,因为不需要遍历到链表的尾部,更不需要保有一个链表尾节点的引用。
如果有被阻塞的离散读请求,中间再混有若干写请求,则会产生多个纵向子队列(栈),此时保有链表尾节点引用的实现方式就显得不切合实际了。
如果线程E是获取读锁,那么栈中节点的顺序是节点B、E、D和C。如果有第6个线程获取锁,不论是它是获取读锁还是写锁,都会排在节点E之后,同时节点E的状态会被设置为-1,即等待状态。
写锁的获取与释放
获取写锁的流程主要包括两部分,尝试获取写锁并自旋入队和队列中自旋获取写锁。如果打开StampedLock源码,会发现获取写锁的逻辑看起来十分复杂,实现包含了大量的循环以及分支判断,而主要逻辑并不是在一个分支中就完成的,而是由多次循环逐步达成。获取写锁的主要流程如下图所示:
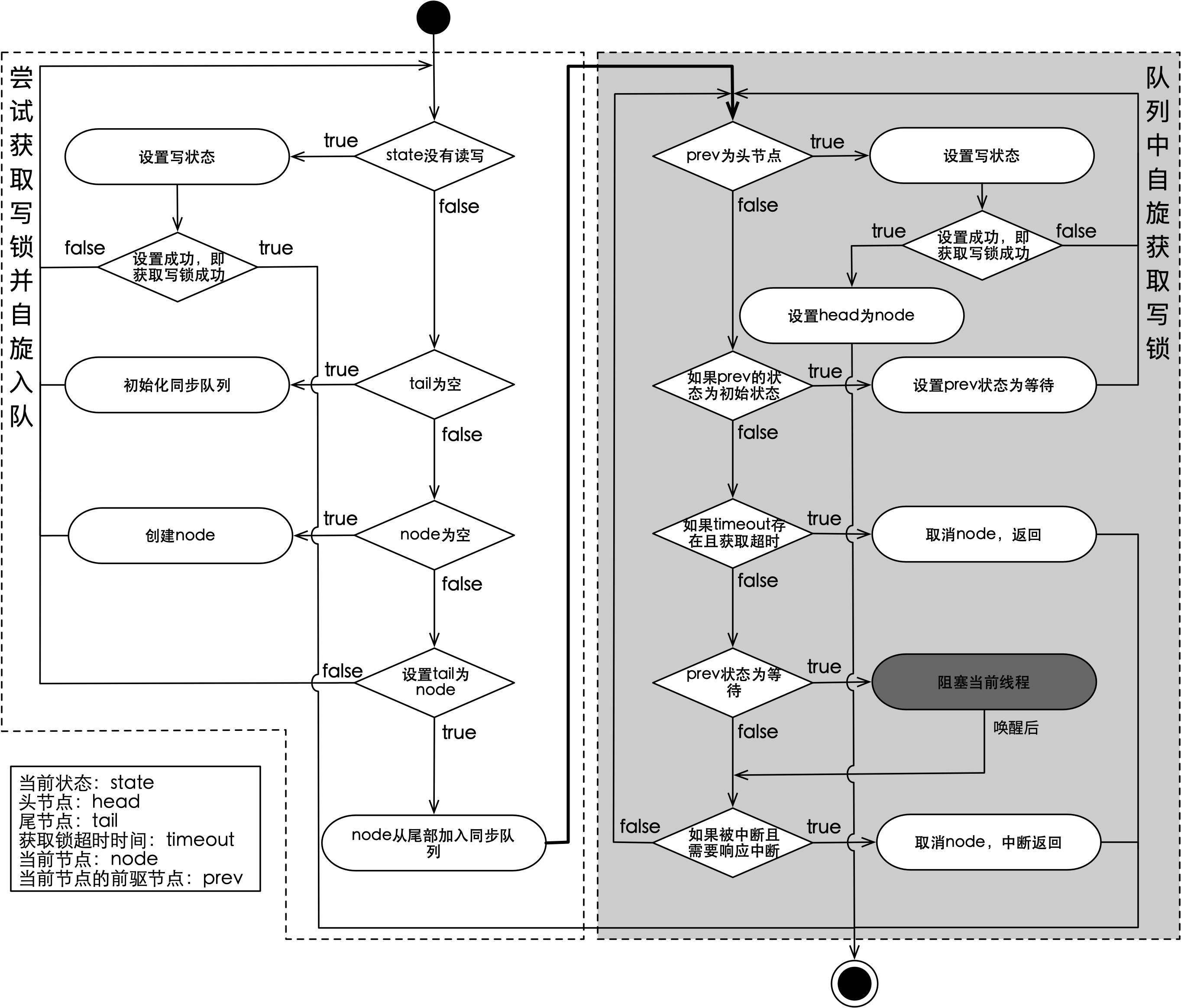
如上图所示,左右两侧分别对应流程的两部分。线程在获取写锁时,首先会尝试自旋获取,而获取的操作就是在没有读写状态的情况下设置写状态,如果设置成功会立刻返回,否则将会创建节点加入到同步队列。接下来,在同步队列中,如果该节点的前驱节点处于等待状态,则会阻塞当前线程。在队列中成功获取写锁的条件是前驱节点是头节点,并成功设置写状态,而被阻塞的线程会被前驱节点的释放操作所唤醒,这点与AQS的同步队列工作机制相似。
成功获取写锁后会得到当前状态的快照,即邮戳,在释放写锁时,需要传入该邮戳,释放写锁的主要流程如下图所示:
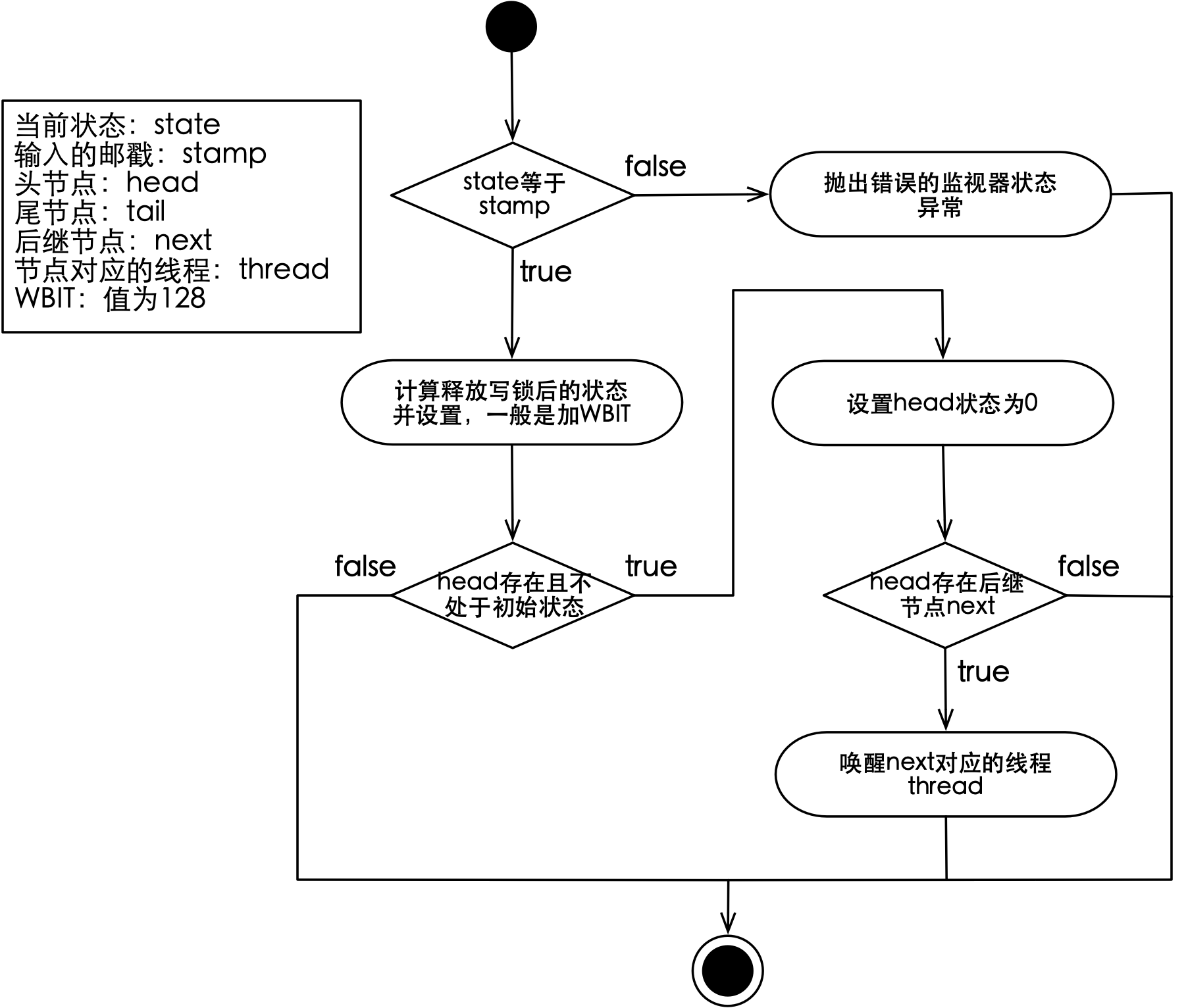
如上图所示,(外部)输入的邮戳与状态理论上应该相同,因为写锁具有排他性,从写锁的获取到释放,状态不会发生改变,所以之前返回的邮戳和当前状态应该相等。释放写锁会唤醒后继节点对应的线程,被唤醒的线程会继续执行先前获取锁的逻辑,在队列中自旋获取写锁。
读锁的获取与释放
获取读锁的流程与写锁类似,但实现要复杂的多,主要原因在于cowait读栈的存在,新加入队列的读类型节点会根据尾节点的类型来执行不同的操作。获取读锁的主要流程如下图所示:
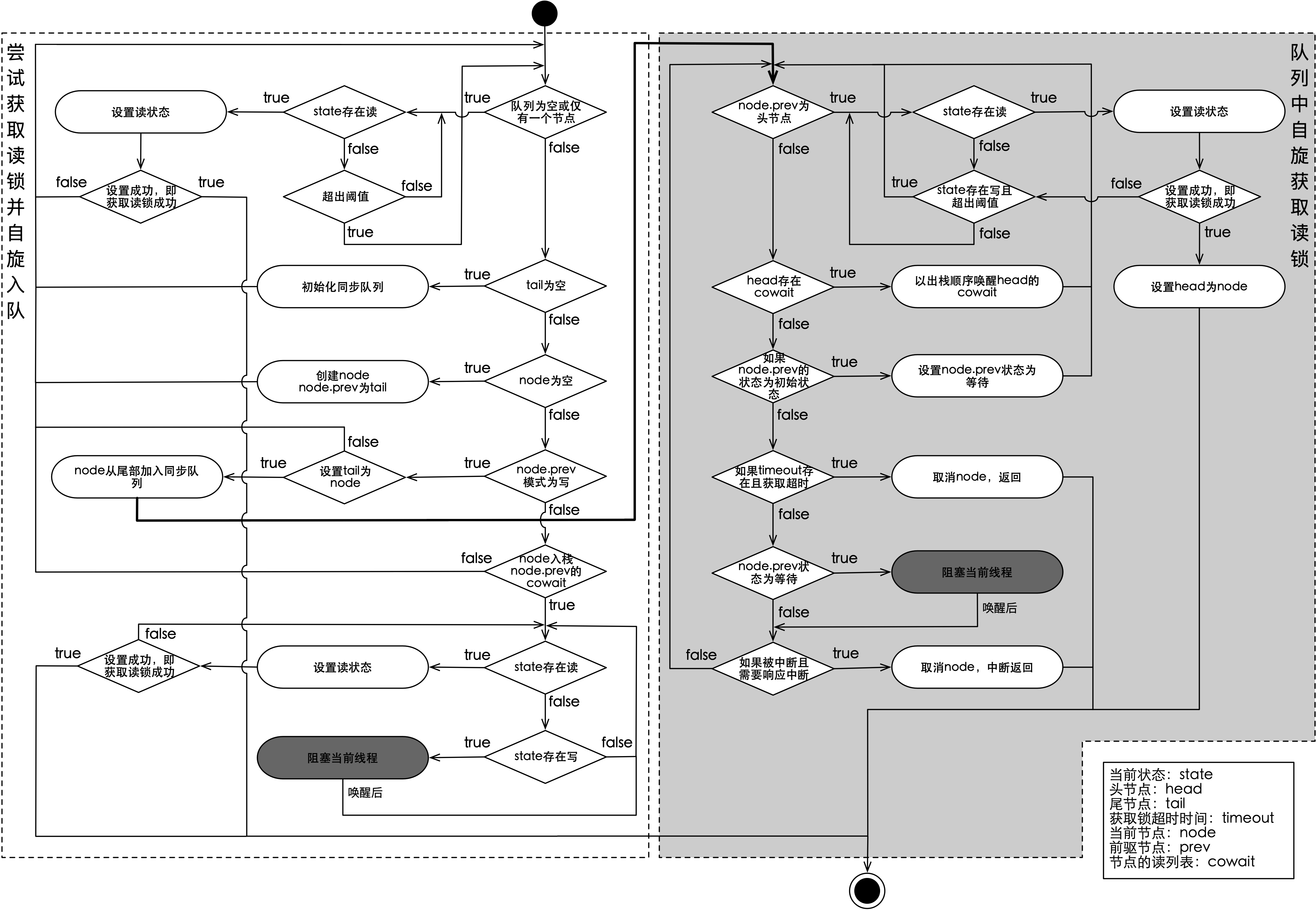
如上图(左侧)所示,在节点node加入到同步队列时,会判断当前尾节点的类型,如果是读类型,就选择入栈尾节点的cowait,否则将会被设置为同步队列的尾节点。进入到cowait读栈的节点会成为栈顶节点的附属,当栈顶节点被唤醒时,它们也会随之被唤醒。进入到横向主队列的节点会尝试自旋获取读锁,当其前驱节点为头节点时,如果锁的状态仅存在读,则进行读状态的设置,设置读状态成功代表获取到了写锁。读状态的设置需要判断现有的读状态是否超出state读状态的上限,如果超过就需要自增readerOverflow。
StampedLock中的state与readerOverflow合力维护了读状态,因此读锁的释放相比写锁要复杂一些,写锁一旦释放就可以唤醒后继节点,而释放读锁不能立刻唤醒后继节点,需要等到读状态减为0时才能执行。释放读锁的主要流程如下图所示:
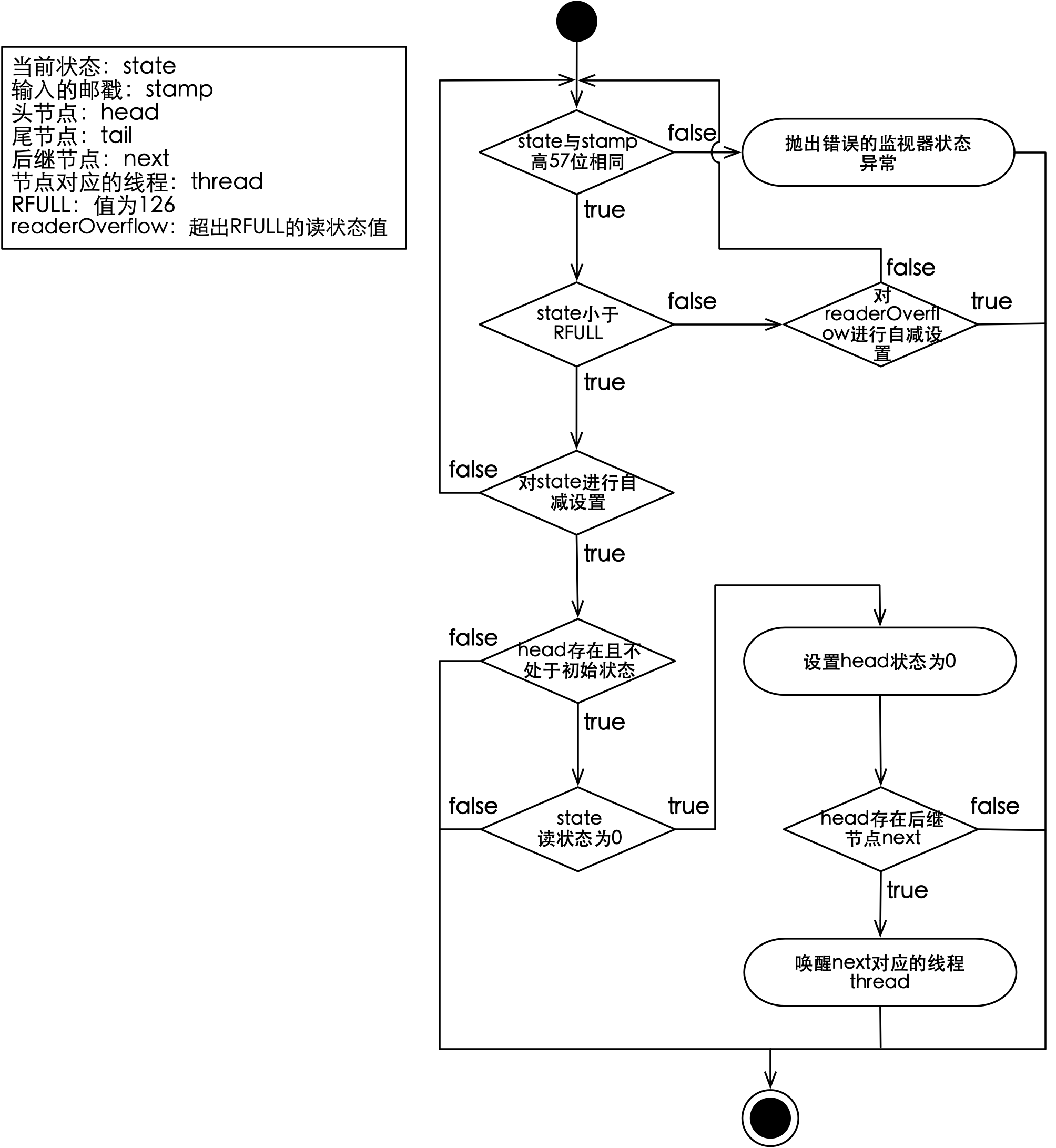
如上图所示,需要先判断当前状态与传入的邮戳,二者的版本(也就是高57位)是否相同,如果相同则会对读状态进行自减操作。当读状态为0时,释放读锁会唤醒后继节点对应的线程,被唤醒的线程会继续执行先前获取读锁的逻辑。
StampedLock为了避免状态以及同步队列头尾指针出现数据不一致的情况,在实现锁的获取与释放时,都会提前将其拷贝到本地变量。实现涉及到大量的for循环和if判断,使得读懂它需要花些时间,建议读者结合流程图阅读一下源码,感受一下作者(Doug Lea)缜密的逻辑。