拉模式的分布式锁
拉模式的分布式锁,需要实例(通过客户端)以自旋的形式,主动去调用存储服务,根据调用结果来判断是否获取到了锁。

什么是拉模式?
拉模式的分布式锁,需要实例(通过客户端)以自旋的形式,主动去调用存储服务,根据调用结果来判断是否获取(或释放)到了锁。这需要存储服务提供类似ConcurrentMap中的原子新增和删除功能。在拉模式的分布式锁中,实例和存储服务的结构如下图所示:
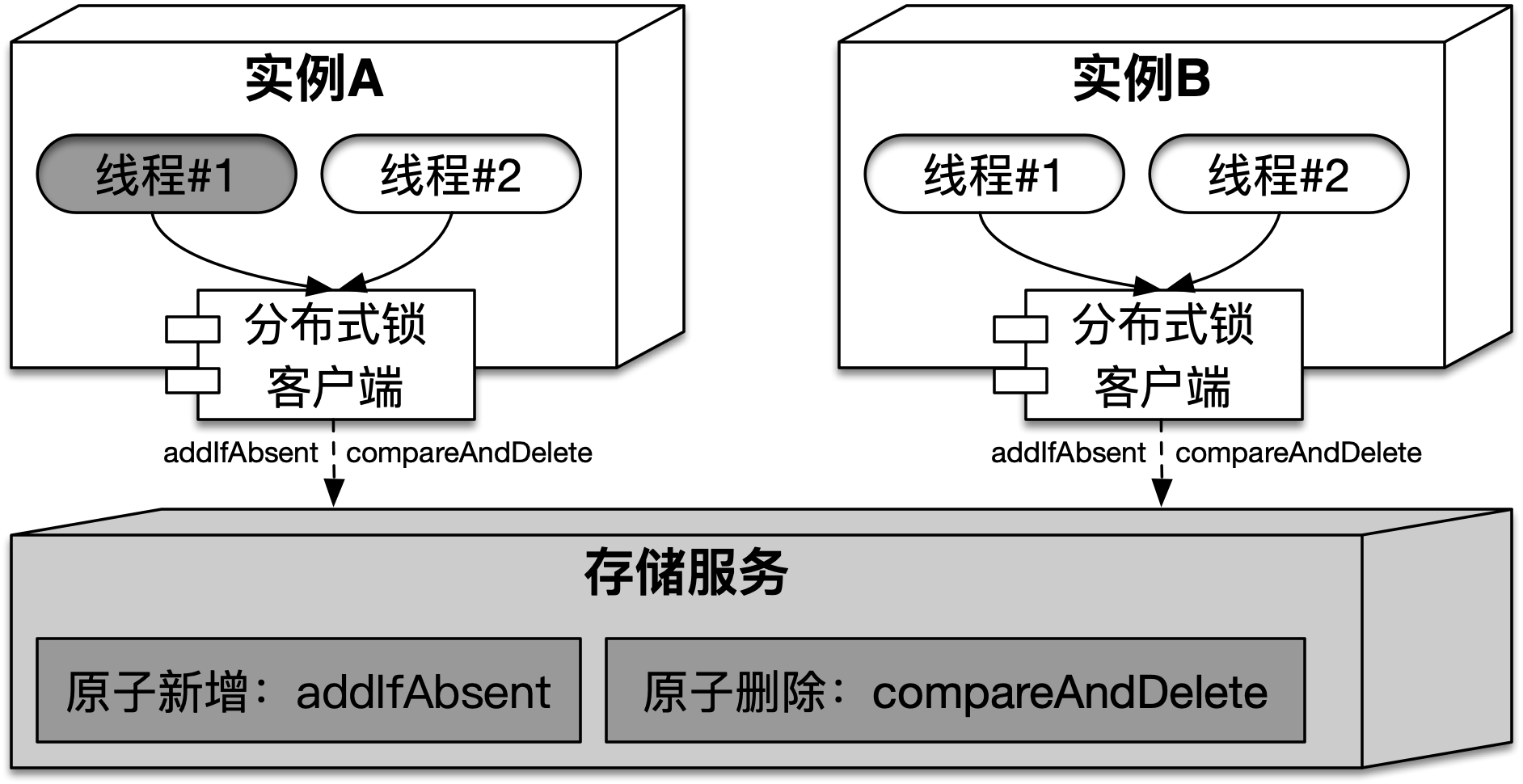
在获取拉模式分布式锁时,需要使用addIfAbsent在存储服务中新增锁对应的资源状态(或一行记录),它需要包含能够代表获取锁的实例(或线程)标识,并且该标识能够确保全局唯一,不同获取锁的实例标识各不相同。释放锁时,需要通过当前实例(或线程)标识,使用compareAndDelete(以下简称:CAD)来删除存储服务中对应的资源状态。存储服务提供的上述功能以及描述,如下表所示:
| 名称 | 参数说明 | 功能 | 描述 |
|---|---|---|---|
addIfAbsent(key, value, ttl) |
key,键,对应锁的名称,全局唯一value,值,与键对应,在删除时可以提供比对功能ttl,过期时间,键新增后,在ttl时间过后,会自动删除 |
原子新增 | 如果已经存在key,则会返回新增失败,否则新增键值成功,且过期时间在ttl之后。该过程需要保证原子性 |
compareAndDelete(key, value) |
同上 | 原子删除 | 只有待删除键key对应的值与参数值value相等,才能够删除该键值。该过程需要保证原子性 |
每一个分布式锁,都对应于存储服务上的一个键,可以将存储服务认为是一个巨大(且线程安全)的Map。如果通过调用addIfAbsent能够成功的新增一个键值,则代表成功获取到了锁。获取拉模式分布式锁的流程如下图所示:
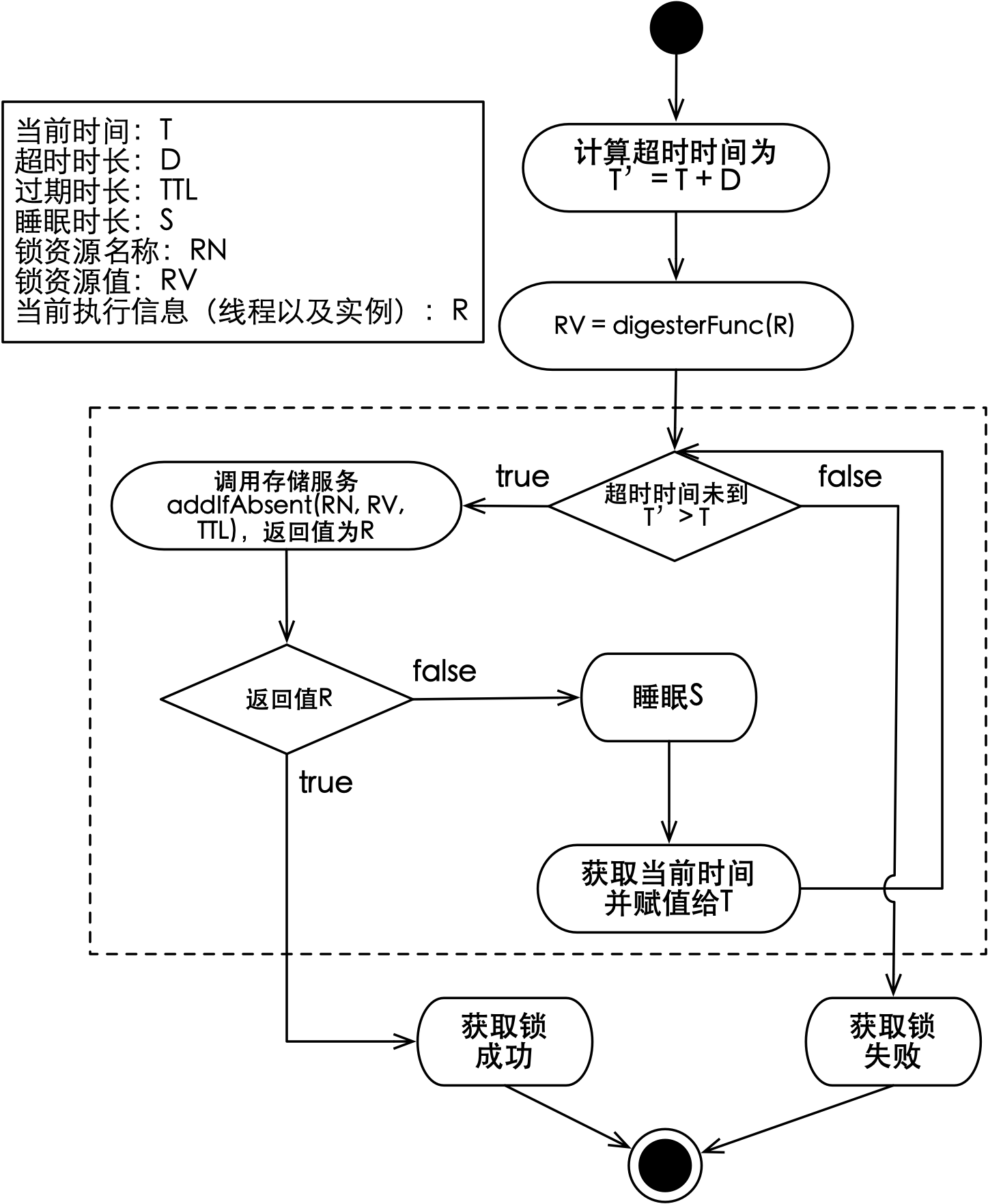
如上图所示,虚线框中的流程就是获取锁的自旋过程,但在介绍它之前,先要看一下获取锁时需要确定的输入,这些输入变量的名称以及描述如下表所示:
| 变量 | 名称 | 描述 |
|---|---|---|
| T | 当前时间 | 当前系统时间 |
| D | 超时时长 | 实例获取锁能够等待的最长时间 |
| TTL | 过期时长 | 资源状态在存储服务上存活的最长时间 |
| S | 睡眠时长 | 新增资源状态(也就是获取锁)失败需要睡眠的时长 |
| RN | 锁资源名称 | 分布式锁的名称,可以是某个业务编号 |
| RV | 锁资源值 | 获取锁的实例标识,需要保证唯一性 |
| R | 当前执行信息 | 获取锁的实例以及线程信息 |
在进入自旋过程前,需要使用digesterFunc函数将R转换为RV。这个函数可以是简单的将实例IP与线程ID的拼接返回,也可以直接返回一个UUID,只要能够确保转换成的RV在这一时刻是全局唯一的,因为在释放锁时,当前线程需要传入该值来完成键值的删除。
在自旋过程中,首先需要判断是否已经超时,如果没有超时,则会使用addIfAbsent尝试新增当前锁的资源状态,资源状态包括名称RN和值RV。由于addIfAbsent具备原子性,多个实例对相同的RN进行新增操作时,只会有一个能够成功,这样就兑现了锁的排他性。
如果调用addIfAbsent返回失败,则表明实例没有获取到锁,此时客户端需要不断的循环重试直至成功,以此来满足实例获取锁的诉求。如果退出循环的条件只是新增资源状态成功,那会带来可用性问题。由于调用存储服务需要通过网络,稍有不慎会导致实例陷入长时间阻塞。因此,循环退出的条件还包括获取锁的超时时间到,每次新增资源状态失败可以睡眠一段时间,避免对存储服务产生过多无效请求。
当释放锁时,实例通过传入锁的资源名称RN和值RV来删除资源状态。由于CAD操作具备先比较再删除的特性,使得只有资源状态中的值与RV相同才能够删除,这就保证了只有获取到锁的实例才能删除资源状态并释放锁,同时多次执行删除操作也是无副作用的。
需要注意的点
拉模式的流程看起来是很简单的,实例通过客户端去获取锁,如果无法在存储服务中新增资源状态,就进行重试,要么超时返回,要么获取到锁。通过一个循环以及少量的时间运算与判断,通过几行代码就可以实现上述逻辑了。如果从能用的角度去看,就是这么简单,但想用的安心,就需要多考虑一点了。拉模式获取锁的主要步骤包括:访问存储服务(调用其新增接口)、时间运算与判断以及睡眠,其中访问存储服务和睡眠对实例获取锁有实际影响,接下来分析它们各自需要被关注的点。
访问存储服务需要注意的点包括:请求的I/O超时、访问存储服务耗时和过期时长设置。首先,请求需要有I/O超时,举个例子:我们经常使用HttpClient去请求Web服务来获取数据,如果Web服务很慢或者网络延迟很高,调用线程就会被挂在那里很久。访问存储服务和这个问题一样,为了避免客户端陷入未知时长的等待,对存储服务的请求需要设置I/O超时。其次,访问存储服务耗时越短越好,如果访问耗时很低,会提升客户端的响应性,当然不同的存储服务访问耗时也会不一样,基于Redis的分布式锁在访问耗时上就优于数据库分布式锁。最后,过期时长支持定制,新增资源状态时会设置过期时长,一般来说这个时长会结合同步逻辑的最大耗时来考虑,是个固定值,比如:10秒。获取锁时,实例其实可以根据当前的上下文估算出可能的耗时,比如:发现同步逻辑中处理的列表数据包含的元素数量比平均数高一倍,如果此时能够适当增加对应的过期时长,会是一个好的选择。这就需要分布式锁框架提供API,能够支持实例设置过期时长,通过设置一个更大的值,就能有效减少由于过期自动释放锁而导致的正确性问题。
过期时长的设置只会影响到本次获取的锁,是基于请求的,不是全局性的。
睡眠需要关注对存储服务产生的压力。对于睡眠而言,简单的做法是固定一个时长,比如:一旦客户端新增资源状态失败,就睡眠15毫秒。如果某个锁资源在多个实例之间有激烈的竞争,这种方式会使得未获取到锁的实例在一个较小的时间范围内同时醒来,并发起对存储服务的重试,无形中增加了存储服务的瞬时压力。如果实例中又以多线程并发的方式获取锁,会导致这个问题变得更糟,解决方式就是引入随机。可以通过指定最小睡眠时长min和随机睡眠时长random来计算本次应该睡眠的时长,每次睡眠时长不固定,只是在[min, min + random)内随机取值。通过随机睡眠会使重试变得离散,一定程度上减轻了对存储服务的压力。
Redis分布式锁实现
分布式锁使用Redis之类的缓存系统来存储锁的资源状态,可以简化其实现方式,毕竟不需要用编程的方式来清除过期的资源状态,因为缓存系统固有的过期机制可以很好的处理这项工作。通过实现LockRemoteResource接口,可以将Redis适配成为分布式锁实现,并集成到框架中。Redis能够满足拉模式分布式锁对存储服务的诉求,综合考虑性能和成本,它非常适合作为拉模式的分布式锁实现。
在分布式锁框架中,介绍了Redis分布式锁实现(RedisLockRemoteResource)的构造函数以及其涉及的参数变量,接下来从获取和释放锁两个方面来介绍实现内容。
Redis分布式锁的获取
Redis作为存储服务的新增接口,需要使用类似命令:SET $RN $RV NX PX $D。该命令通过NX选项,确保只有在键(也就是$RN)不存在的情况下才能设置(添加),同时PX选项表示该键将会在$D毫秒后过期,而值$RV需要做到所有客户端唯一。
使用Lettuce客户端,上述操作的代码如下所示:
private boolean lockRemoteResource(String resourceName, String resourceValue, int ownSecond) {
SetArgs setArgs = SetArgs.Builder.nx().ex(ownSecond);
boolean result = false;
try {
String ret = syncCommands.set(resourceName, resourceValue, setArgs);
// 返回是OK,则锁定成功,否则锁定资源失败
if ("ok".equalsIgnoreCase(ret)) {
result = true;
}
} catch (Exception ex) {
throw new RuntimeException("set key:" + resourceName + " got exception.", ex);
}
return result;
}
上述方法提供了基于Redis的addIfAbsent语义,且支持过期时长的一并设置。参数SetArgs使用构建者模式创建,syncCommands是Lettuce提供的RedisCommands接口,由于当前逻辑需要同步获得设置的结果,所以采用同步模式。
获取锁的方法,代码如下所示:
public AcquireResult tryAcquire(String resourceName, String resourceValue, long waitTime,
TimeUnit timeUnit) throws InterruptedException {
// 目标最大超时时间
long destinationNanoTime = System.nanoTime() + timeUnit.toNanos(waitTime);
boolean result = false;
boolean isTimeout = false;
Integer liveSecond = OwnSecond.getLiveSecond();
int ownTime = liveSecond != null ? liveSecond : ownSecond;
AcquireResultBuilder acquireResultBuilder;
try {
while (true) {
// 当前系统时间
long current = System.nanoTime();
// 时间限度外,直接退出
if (current > destinationNanoTime) {
isTimeout = true;
break;
}
// 远程获取到资源后,返回;否则,spin
if (lockRemoteResource(resourceName, resourceValue, ownTime)) {
result = true;
break;
} else {
spin();
}
}
acquireResultBuilder = new AcquireResultBuilder(result);
if (isTimeout) {
acquireResultBuilder.failureType(AcquireResult.FailureType.TIME_OUT);
}
} catch (Exception ex) {
acquireResultBuilder = new AcquireResultBuilder(result);
acquireResultBuilder
.failureType(AcquireResult.FailureType.EXCEPTION)
.exception(ex);
}
return acquireResultBuilder.build();
}
上述方法,首先将获取锁的超时时间单位统一到纳秒,由超时时长waitTime计算出最大的超时时间destinationNanoTime。在接下来的自旋中,如果当前系统时间current大于destinationNanoTime就会超时返回。如果调用存储服务返回新增失败,则会执行spin()方法进行睡眠,而睡眠的时长为:ThreadLocalRandom.current().nextInt(randomMillis) + minSpinMillis,它会在一个时间范围内进行随机,以此避免对存储服务产生无谓的瞬时压力。
可以通过OwnSecond工具对资源状态的占用时长(也就是Redis键值的过期时间)进行自定义设置。如果需要更改本次调用对于锁的占用时长,可以在调用锁的tryLock()方法之前,执行OwnSencond.setLiveSecond(int second)方法,该工具依靠ThreadLocal将实例设置的占用时长传递给框架。
Redis分布式锁的释放
释放锁可以通过资源名称RN和资源值RV删除对应的资源状态即可,但该过程必须是原子化的。如果是先根据RN查出资源状态,再比对RV与资源状态中的值是否一样,最后使用del命令删除对应键值,这样的两步走会导致锁有被误释放的可能,该过程如下图所示:
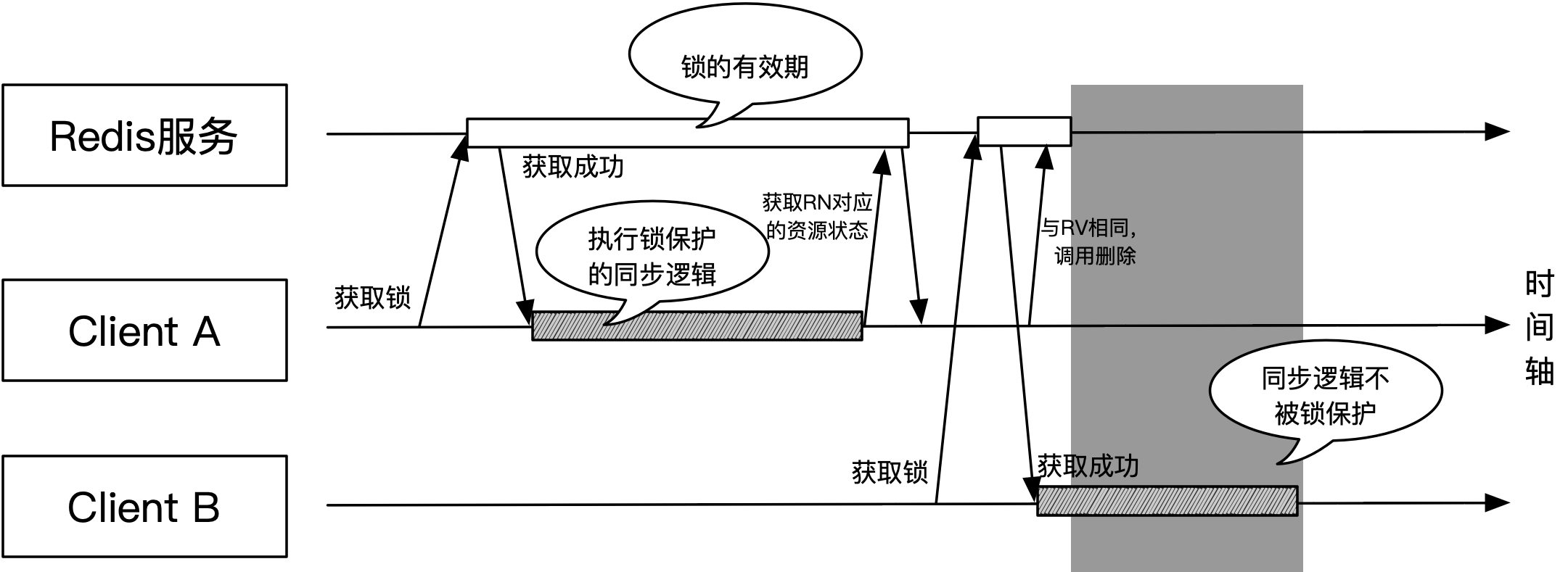
如上图所示,客户端A在锁的有效期(也就是占用时长)快结束时调用了unlock()方法。如果采用两步走逻辑,在使用del命令删除键值前,锁由于超时时间到而自动释放,此时客户端B成功获取到了锁,并开始执行同步逻辑。客户端A由于(旧)值比对通过,使用del命令删除了资源状态对应的键值,这时运行在客户端B上的同步逻辑就不会再受到锁的保护,因为其他实例可以获取到锁并执行。
Redis可以通过Lua脚本做到原子化CAD的支持,脚本如下:
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
可以看到其实就是两步走逻辑的Lua版本,只是Redis对于Lua脚本的执行是确保原子性的。
如果使用阿里云的RDB缓存服务,可以使用其
cad扩展命令,不使用上述脚本。
释放锁的方法,代码如下所示:
public void release(String resourceName, String resourceValue) {
try {
syncCommands.eval(
"if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end",
ScriptOutputType.INTEGER, new String[]{resourceName}, resourceValue);
} catch (Exception ex) {
// Ignore.
}
}
上述方法通过调用RedisCommands的eval()方法执行CAD脚本来安全的删除资源状态来完成锁的释放。
Redis分布式锁存在的问题
主从切换带来的问题
如果存储服务出现故障,则会导致分布式锁不可用,为了确保其可用性,一般会将多个存储服务节点组成集群。以Redis为例,使用主从集群可以提升分布式锁服务的可用性,但是它会带来正确性被违反的风险。
Redis主从集群会在所有节点上保有全量数据,主节点负责数据的写入,然后将变更异步同步到从节点。这种同步模式会导致在主从切换的一段时间内,由于新旧主节点上的数据不对等,导致部分分布式锁存在可能被多个实例同时获取到的风险,该过程如下图所示:
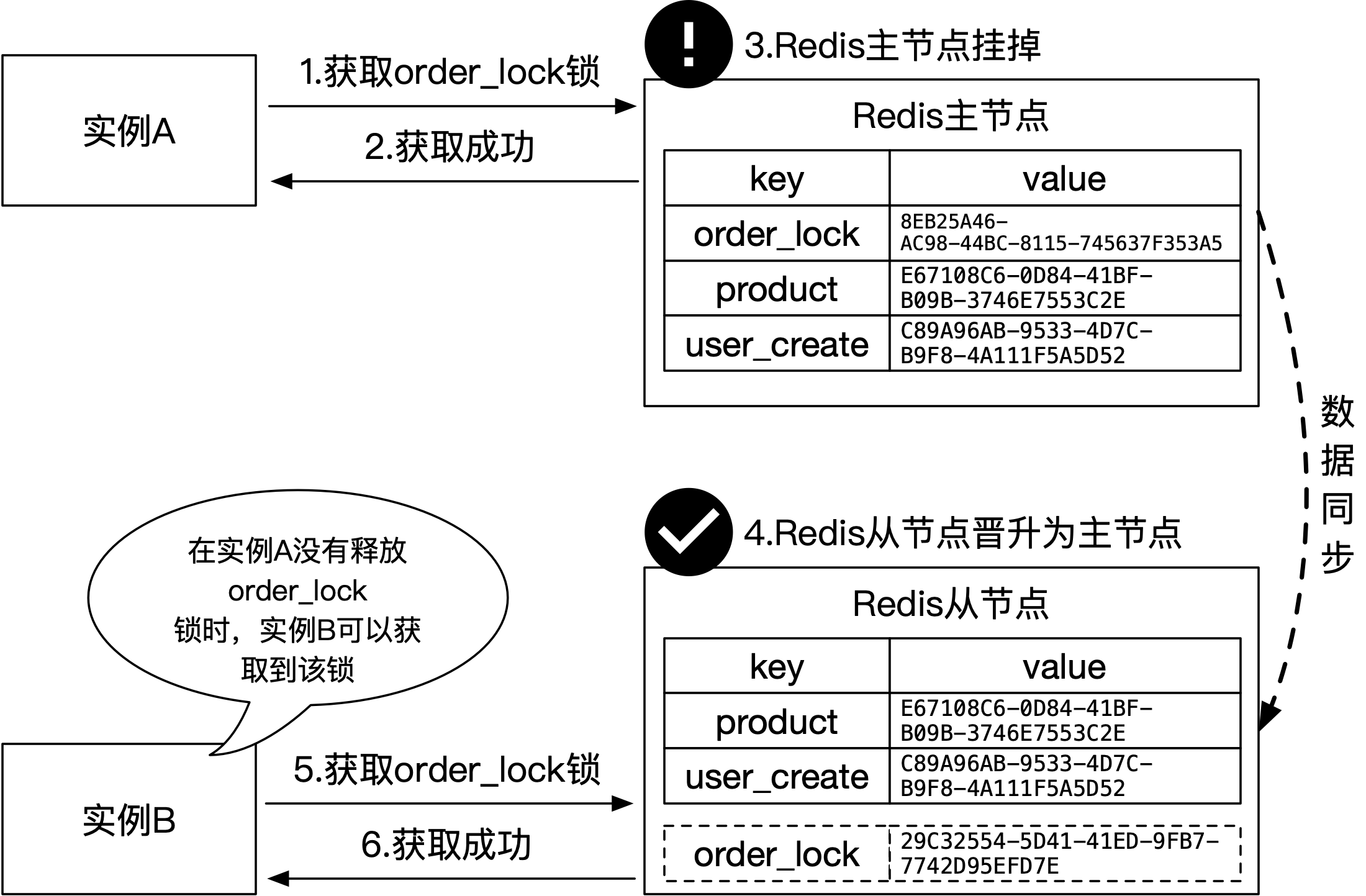
上图中,主从集群可以提升分布式锁的可用性,避免出现由于Redis节点挂掉后导致的不可用。虽然可用性提升了,但是正确性会下降。在步骤1到2过程中,实例A先成功的在切换前的Redis主节点上新增了记录,也就是获取到了order_lock锁。随后Redis主节点挂掉,集群进行主从切换,数据仍在异步的向新晋升的Redis主节点上同步。步骤5到6,实例B刚好此时获取锁,它会尝试在新晋Redis主节点上新增记录,由于数据并未在此时完成同步,所以实例B成功的新增了记录并获取到了order_lock锁。在这一刻,实例A和B都会宣称获取到了order_lock锁,而相应的同步逻辑也会被并行执行,锁的正确性被违反。
看似完美的Redlock
Redis单节点是CP型存储服务,使用它可以满足分布式锁对于正确性的诉求,但存在可用性问题。使用Redis主从集群技术后,会转为AP型存储服务,虽然提升了分布式锁的可用性,但正确性又会存在风险。面对可用性和正确性两难的局面,Redis作者(Salvatore)设计了不基于Redis主从技术的Redlock算法,该算法使用多个Redis节点,使用基于法定人数过半(Quorum)的策略,以期望该算法能做到正确性与可用性的兼得。
Redlock需要使用多个Redis节点来实现分布式锁,节点数量一般是奇数,并且至少要5个节点才能使其具备良好的可用性。该算法是一个客户端算法,也就是说它在每个客户端上运行方式是一致的,且客户端之间不会进行相互通信。接下来以5个节点为例,Redlock算法过程如下图所示:
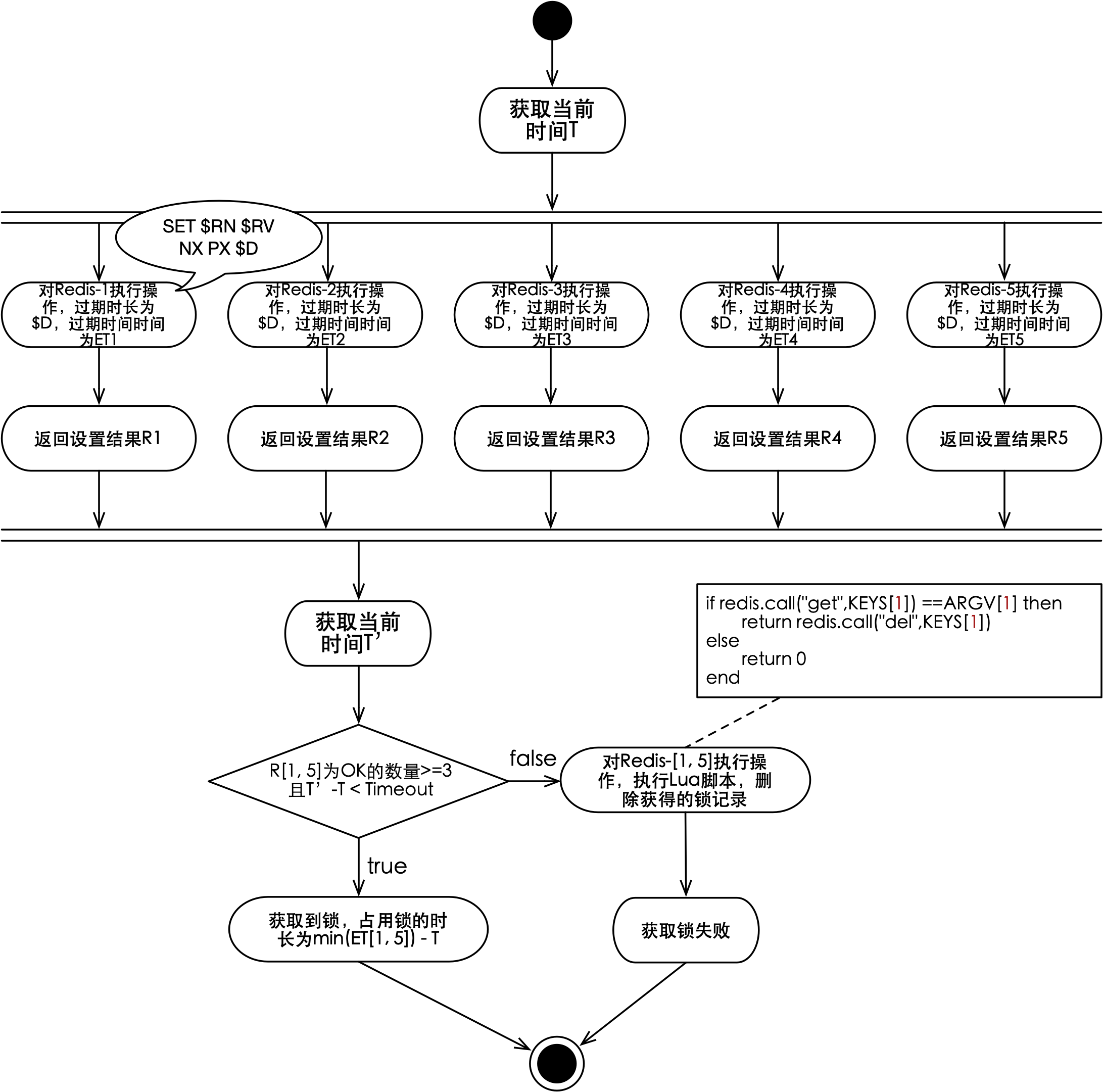
如上图所示,首先Redlock算法会获取当前时间T,然后使用相同的锁资源名称$RN和资源值$RV并行的向5个Redis节点进行操作。执行的操作与获取单节点Redis分布式锁的操作一致,如果对应的Redis节点上不存在$RN则会成功设置,且过期时长为$D。对5个Redis节点进行设置的结果分别为R1至R5,再取当前时间T’,如果结果成功数量大于等于3且 (T’-T)小于$D,表明在多数Redis节点上成功新增了$RN且这些键均没有过期,则代表客户端获取到了锁,有效期为ET1至ET5的最小值减去T。
如果设置结果成功数量小于3,表明在多个Redis节点上,对于新增$RN没有寻得共识。如果 (T’-T)大于等于$D,表明当前客户端获取的锁已经超时。上述两种情况只要出现一个,则客户端获取锁失败。此时需要在所有Redis节点上运行无副作用的删除脚本,将当前客户端创建的记录(如果有的话,就)删除,避免记录要等到超时才能被清除。
分布式锁框架通过使用Redisson客户端,可以很容的将Redlock集成到框架中,该分布式锁实现代码可以参见分布式锁项目中的distribute-lock-redlock-support模块。
Redlock算法看起来能够在分布式锁的可用性和正确性之间寻得平衡,少量Redis节点挂掉,不会引起分布式锁的可用性问题,同时正确性又得以保证。理想情况下,Redlock看似很完美,但在分布式环境中,进程的暂停或网络的延迟,会打破该算法,使之失效。以Java应用为例,如果在算法判定获取到锁,客户端执行同步逻辑时引入GC暂停,则会可能导致该算法对于正确性的保证失效,该过程如下图所示:
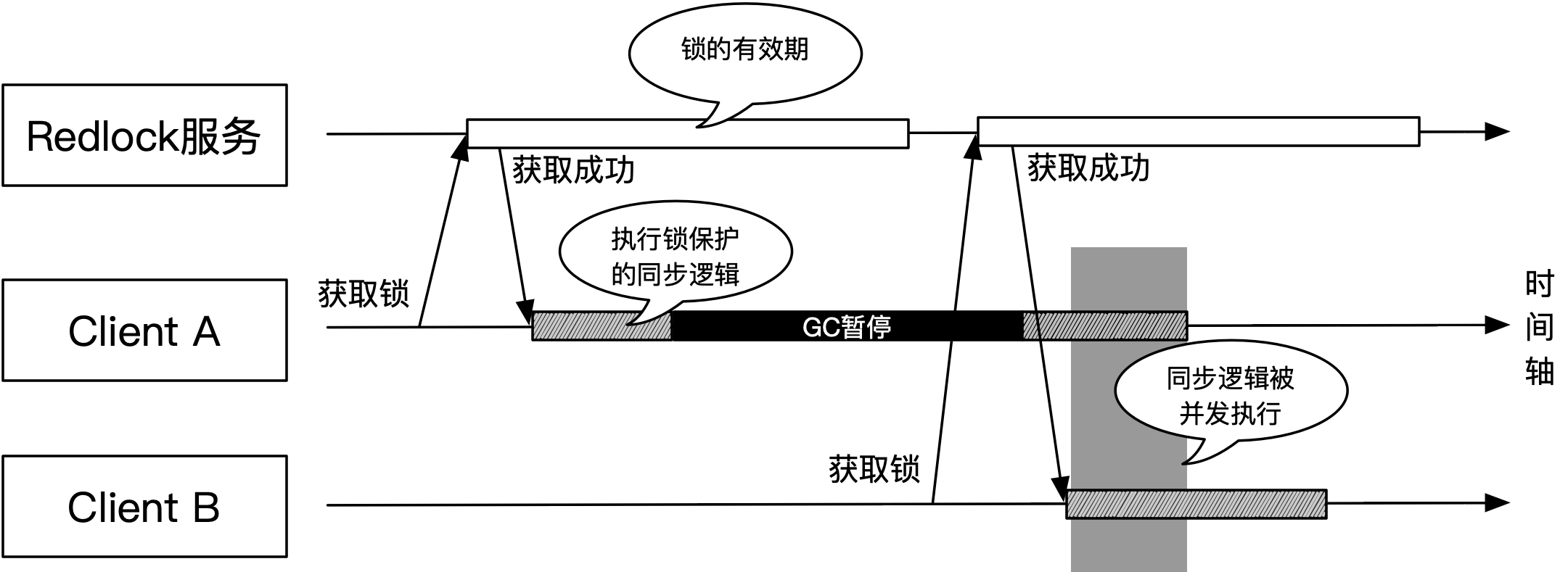
如上图所示,客户端A获取到了锁,然后开始执行锁保护的同步逻辑,该逻辑在同一时刻只能有一个客户端能够执行。当客户端A开始执行逻辑时,由于GC导致进程出现停顿(GC暂停,即stop-the-world,不会由于运行的是业务线程而对其特殊对待,它会一律暂停Java虚拟机中除GC外的线程),而暂停时长超出了锁的有效期,此时锁已经由于超时而释放。
客户端B在锁超时后获取到了锁,然后开始执行同步逻辑,客户端A由于GC结束而恢复执行,此时原本被锁保护的同步逻辑被并发执行,锁的正确性被违反。
可以看到虽然Redlock算法通过基于法定人数的设计,在理论上确保了正确性和可用性,但是在真实的分布式环境中,会出现正确性无法被保证的风险。有同学会问,如果使用没有GC特性的编程语言来开发应用,是不是就可以了?实际上除了GC导致进程暂停,如果同步逻辑中有网络交互,也可能由于TCP重传等问题导致实际的执行时间超出了锁的有效期,最终导致两个客户端又有可能并发的执行同步逻辑。
单节点(或主从集群)的Redis分布式锁也存在上述问题,本质在于基于Redis实现的分布式锁,对于锁的释放存在超时时间的假设。虽然超时避免了死锁,但是会导致锁超时(释放)的一刻,两个客户端有同时进行操作的可能,这是能够在理论模型上推演出来的,毕竟释放锁的不是锁的持有者,而是锁自己。
扩展:本地热点锁
拉模式分布式锁需要依靠不断的对存储服务进行自旋调用,来判断是否能够获取到锁,因此会产生大量的无效调用,平添了存储服务的压力。对于分布式锁而言,竞争的最小单位不是进程,而是线程,由于实际情况中的(应用)实例都是以多线程模式运行的,导致竞争会更加激烈。
在激烈的竞争中,如果遇到热点锁,情况会变得更糟。比如:使用商品ID作为锁的资源名称,对于爆款商品而言,多机多线程就会给存储服务带来巨大的压力,该问题如下图所示:
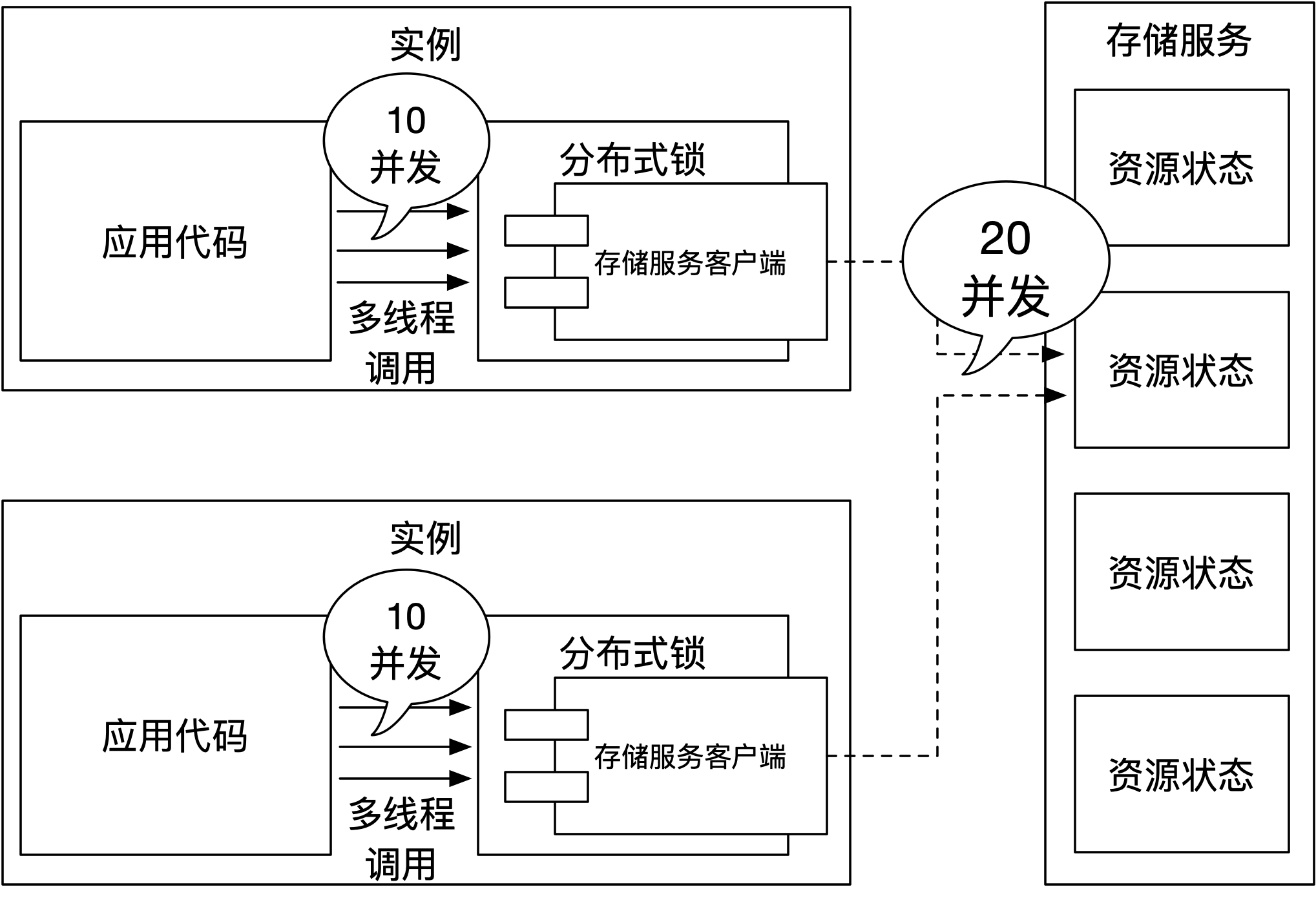
如上图所示,实例内通过多线程并发的方式获取锁。在单个实例内,假设获取商品锁的并发度是10,那么两个实例就能够给存储服务带来20个并发的调用。以线程的角度来看这20个并发,是合理的,虽然每次请求绝大部分都是无功而返(没有获取到锁),但是这都是为了保证锁的正确性,纵使再高的并发,也只能通过不断的扩容存储服务来抵消增长的压力。
可以想象,存储服务上处理的请求,基本全都是无效的,不断的扩容存储服务显得不现实,是否有其他方法可以优化这个过程呢?答案就是通过本地热点锁来解决。通过使用(单机)本地锁可以有效的降低对存储服务产生的压力,该过程如下图所示:
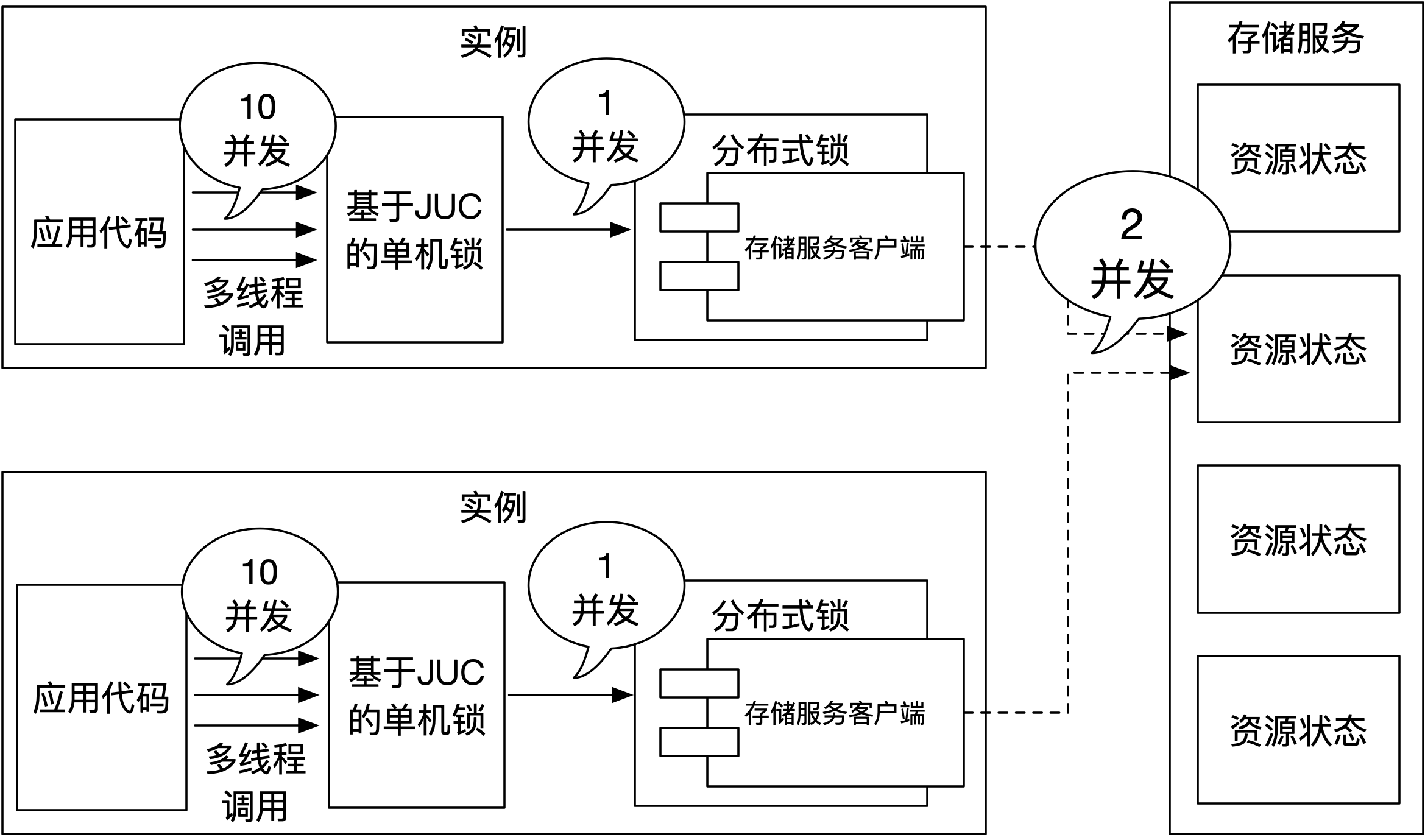
如上图所示,实例中的多线程应该先尝试竞争本地(基于JUC的单机)锁,成功获取到本地锁的线程才能参与到实例间的分布式锁竞争。从实例的角度去看,如果都是获取同一个分布式锁,在同一时刻只能由一个实例中的一个线程获取到锁,因此理论上对存储服务的并发上限只需要和实例数一致,也就是2个并发就可以了。
可以通过在分布式锁前端增加一个本地锁就能得以实现,但事实上并没有这么容易,因为实例中的多线程需要使用同一把本地锁才会有意义,所以需要有一个Map结构来保存锁资源名称到本地锁的映射。如果对该结构管理不当,对任意分布式锁的访问都会创建并保有本地锁,那就会使实例有OOM的风险。一个比较现实的做法就是针对某些热点锁进行优化,只创建热点锁对应的本地锁来有效减少对存储服务产生的压力。
在实际工作场景中,可以根据生产数据发现实际的热点数据,比如:爆款商品ID或热卖商家ID等,将其提前(或动态)设置到分布式锁框架中,通过将分布式锁“本地化”,来优化这个过程。
由于本地锁的获取是在分布式锁之前,通过扩展分布式锁框架的LockHandler就可以很好的支持这一特性,对应的LockHandler扩展(的部分)代码如下:
package io.github.weipeng2k.distribute.lock.plugin.local.hotspot;
import io.github.weipeng2k.distribute.lock.spi.AcquireContext;
import io.github.weipeng2k.distribute.lock.spi.AcquireResult;
import io.github.weipeng2k.distribute.lock.spi.ErrorAware;
import io.github.weipeng2k.distribute.lock.spi.LockHandler;
import io.github.weipeng2k.distribute.lock.spi.ReleaseContext;
import io.github.weipeng2k.distribute.lock.spi.support.AcquireResultBuilder;
import org.springframework.core.annotation.Order;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
/**
* <pre>
* 本地热点锁LocalHandler
*
* 获取锁时,会先获取本地的锁,然后尝试获取后面的锁
* 如果后面的锁获取成功,则返回
* 如果后面的锁获取失败,则需要解锁
*
* 释放锁时,会先释放后面的锁,然后尝试释放当前的锁,不要抛出错误即可
*
* </pre>
*
* @author weipeng2k 2021年12月14日 下午18:43:29
*/
@Order(10)
public class LocalHotSpotLockHandler implements LockHandler, ErrorAware {
private final LocalHotSpotLockRepo localHotSpotLockRepo;
public LocalHotSpotLockHandler(LocalHotSpotLockRepo localHotSpotLockRepo) {
this.localHotSpotLockRepo = localHotSpotLockRepo;
}
@Override
public AcquireResult acquire(AcquireContext acquireContext, AcquireChain acquireChain) throws InterruptedException {
AcquireResult acquireResult;
Lock lock = localHotSpotLockRepo.getLock(acquireContext.getResourceName());
if (lock != null) {
// 先获取本地锁
if (lock.tryLock(acquireContext.getRemainingNanoTime(), TimeUnit.NANOSECONDS)) {
acquireResult = acquireChain.invoke(acquireContext);
// 没有获取到后面的锁,则进行解锁
if (!acquireResult.isSuccess()) {
unlockQuietly(lock);
}
} else {
AcquireResultBuilder acquireResultBuilder = new AcquireResultBuilder(false);
acquireResult = acquireResultBuilder.failureType(AcquireResult.FailureType.TIME_OUT)
.build();
}
} else {
acquireResult = acquireChain.invoke(acquireContext);
}
return acquireResult;
}
@Override
public void release(ReleaseContext releaseContext, ReleaseChain releaseChain) {
releaseChain.invoke(releaseContext);
Lock lock = localHotSpotLockRepo.getLock(releaseContext.getResourceName());
if (lock != null) {
unlockQuietly(lock);
}
}
private void unlockQuietly(Lock lock) {
try {
lock.unlock();
} catch (Exception ex) {
// Ignore.
}
}
}
可以看到,本地热点锁都存储在LocalHotSpotLockRepo中,由使用者进行设置。通过DistributeLock获取锁时,框架会先从LocalHotSpotLockRepo中查找本地锁,如果没有找到,则执行后续的LockHandler,反之,会尝试获取本地锁。需要注意的是,成功获取到本地锁后,如果接下来没有获取到分布式锁,就需要释放当前的本地锁,避免阻塞其他线程获取分布式锁的行为。
对于释放锁而言,需要在releaseChain.invoke(releaseContext);语句之后释放本地锁,也就是在分布式锁(的存储服务)被释放后,再释放本地锁。如果释放顺序反过来,提前释放了本地锁,会使得被(释放本地锁而)唤醒的线程立刻向存储服务发起无效请求。
上述功能以插件的形式提供给使用者,只需要依赖如下坐标就可以激活使用:
<dependency>
<groupId>io.github.weipeng2k</groupId>
<artifactId>distribute-lock-local-hotspot-plugin</artifactId>
</dependency>
该插件会在应用的Spring容器中注入LocalHotSpotLockRepo,通过调用它的
createLock(String resourceName)方法完成本地锁的创建。
接下来通过两个测试用例:distribute-lock-redis-testsuite和distribute-lock-redis-local-hotspot-testsuite来展示本地热点锁的优化效果。考察的指标是通过执行Redis提供的info commandstats来查看SET命令执行的数量来进行判定的,因为获取分布式锁就是依靠SET命令。
两个测试用例都会运行3个实例,分两个批次执行,获取的分布式锁名称都是lock_key。每个实例都会以4个并发获取分布式锁,尝试获取400次,数据对比如下表所示:
| 用例 | 执行前SET命令数量 | 执行后SET命令数量 | 获取锁成功数量 | 获取锁失败数量 | 对Redis的SET请求数量 |
|---|---|---|---|---|---|
| Redis锁测试集 | 183168 | 204413 | 1099 | 101 | 21245 |
| Redis锁测试集(包含本地热点锁插件) | 204413 | 210518 | 1147 | 53 | 6105 |
如上表所示,可以看到本地热点锁插件能够显著的降低热点锁对存储服务的请求,有70%的无效请求被该插件所阻挡。随着对Redis请求量的下降,分布式锁获取成功率也随之上升。