程序!程序!程序!—— 编译的力量
如果说操作系统是程序运行的基础,那么编译器就是源代码到程序的助产士,编译的过程如同分娩,编译器承担孵化应用程序过程中难以想象的复杂和困难,经历了一道道的工序,最终程序能够如同新生儿一样呱呱坠地,我们在赞美程序功能的同时,也能感受到编译的伟力。

从源代码到程序(或者说可执行文件)指的就是编译,但我们所说的编译实际上是一个比较笼统的概念,其实它是由三部分构成的,如下图所示:
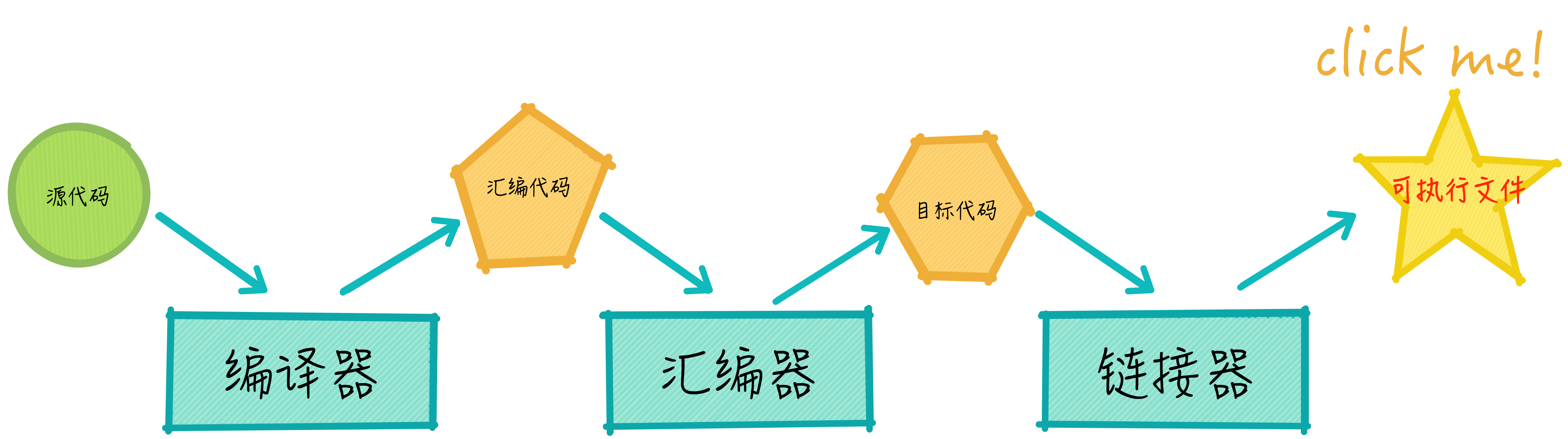
如上图所示,编译器先将程序源代码翻译为汇编代码,再由汇编器将汇编代码转换为二进制的目标文件,最后目标文件由链接器将其与运行环境进行链接,生成出可执行文件。接下来用一个C语言例子演示一下这个过程,代码如下:
#include <stdio.h>
int main() {
printf("你好!\n");
return 0;
}
首先将源代码保存为hello.c,然后使用命令cc -S -masm=intel hello.c > hello.s让编译器将将C源代码文件翻译为汇编代码,hello.s(部分)汇编代码如下:
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 12, 0 sdk_version 12, 3
.intel_syntax noprefix
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
push rbp
.cfi_def_cfa_offset 16
.cfi_offset rbp, -16
mov rbp, rsp
.cfi_def_cfa_register rbp
sub rsp, 16
mov dword ptr [rbp - 4], 0
lea rdi, [rip + L_.str]
mov al, 0
call _printf
xor eax, eax
add rsp, 16
pop rbp
ret
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "\344\275\240\345\245\275\357\274\201\n"
.subsections_via_symbols
在前文中已经简单介绍过汇编语言,这种以指令和操作数组成的代码,直接与硬件打交道,看起来简单的语法能够演绎出丰富的特性。接下来,使用命令cc -c hello.s > hello.o,将汇编代码转换为目标文件,目标文件不同于可执行文件,它没有完成本地化,但是它已经被翻译成CPU能够解释执行的本地代码,是二进制形式的,这里就不做展示了。
目标文件还需要生成出可执行文件方能运行,此时链接器就能派上用场,链接器对当前所处的软件环境非常熟悉,知道系统的目标文件(或者库)所在位置。它会将源代码生成的目标文件中 “或缺” 的地方用系统的目标文件加以补充,一旦完成融合,可执行文件就生成了。使用命令cc hello.o -o hello,链接器会将目标文件生成为可执行文件。
链接器所熟悉的系统目标文件,比如:库文件对应的目标文件。
整个源代码编译(和链接)以及可执行文件(或程序)运行的过程,如下所示:
% cc -S -masm=intel hello.c > hello.s
% cc -c hello.s > hello.o
% cc hello.o -o hello
% ./hello
你好!
接下来,分别简单介绍一下编译和链接的过程。
编译的过程
编译的目的是将源代码转换为汇编代码,这个过程中编译器会对源代码进行语法、句法和语义解析,再根据系统运行环境,将源代码转换为汇编代码。不同语言的编译器能够支持各自语言的语义和语法解析,并且它们一般都会有一个对应表,这个对应表一边是自身编程语言的语法模式,而另一边就是汇编指令,编译器需要承担这个翻译的工作。编译器所处的位置,如下图所示:
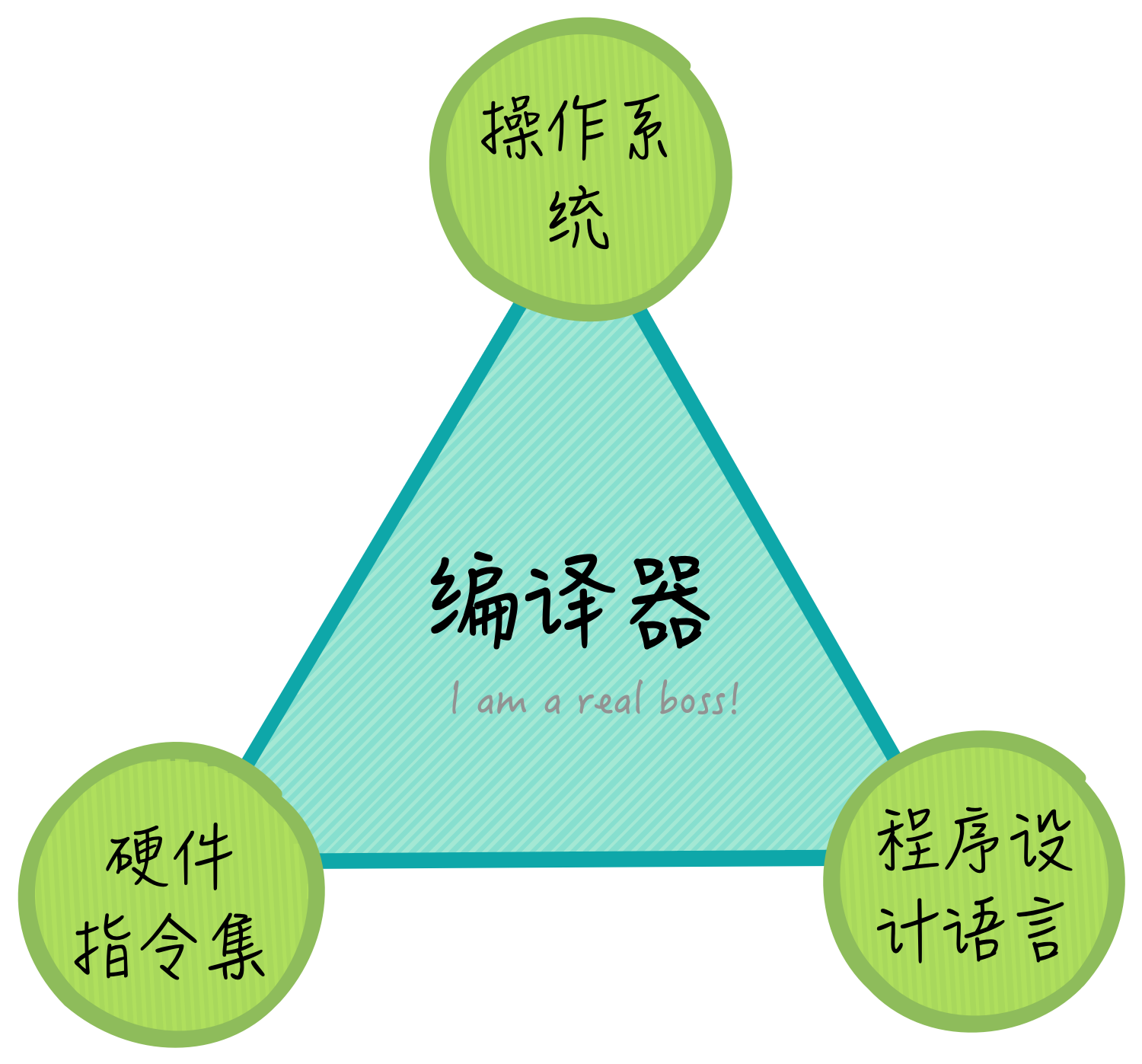
如上图所示,编译器处于操作系统、硬件指令集和编程语言(概念)三者的中心,它需要和三者紧密的联系。编译器和语言相关,这点很自然,毕竟不同语言的语法结构都需要编译器能够理解、支持和翻译。编译器和操作系统相关,不同的操作系统对应用程序的布局、描述和支持都不一样,所以编译器和操作系统是相关的,它需要编译出运行在某种操作系统下的程序。编译器又和硬件指令集相关,硬件指令集狭义上就是CPU指令集,是x86还是arm,这是不一样的,毕竟寄存器和汇编指令都不一样的。
编译器将源代码转换成汇编代码的过程中充满了挑战,编译器不仅应对了这些挑战,还能够在这个过程中进行优化,比如:会尽可能多的使用寄存器,而不是使用(存储在内存中的)栈,原因就是寄存器的效率更高,毕竟离CPU更近一些,相对于访问内存的速度,访问寄存器快了几十倍。如果源代码中有一些用不着的变量声明,或者调用函数后忽略返回值,这些都会被编译器优化掉,可以看出编译器是编程语言设计者同普通开发者之间的桥梁。
链接的过程
汇编代码经过汇编器进行转换后,会生成目标文件,目标文件需要链接后才会生成能够运行在当前环境的可执行文件。程序想在运行环境中启动,需要得到软(操作系统)和硬(CPU指令集)的支持,目标文件已经与硬做好了适配,还需要同软打通,即目标文件需要同操作系统中已有的目标文件进行链接,才能使用操作系统提供的能力,这个过程如下图所示:
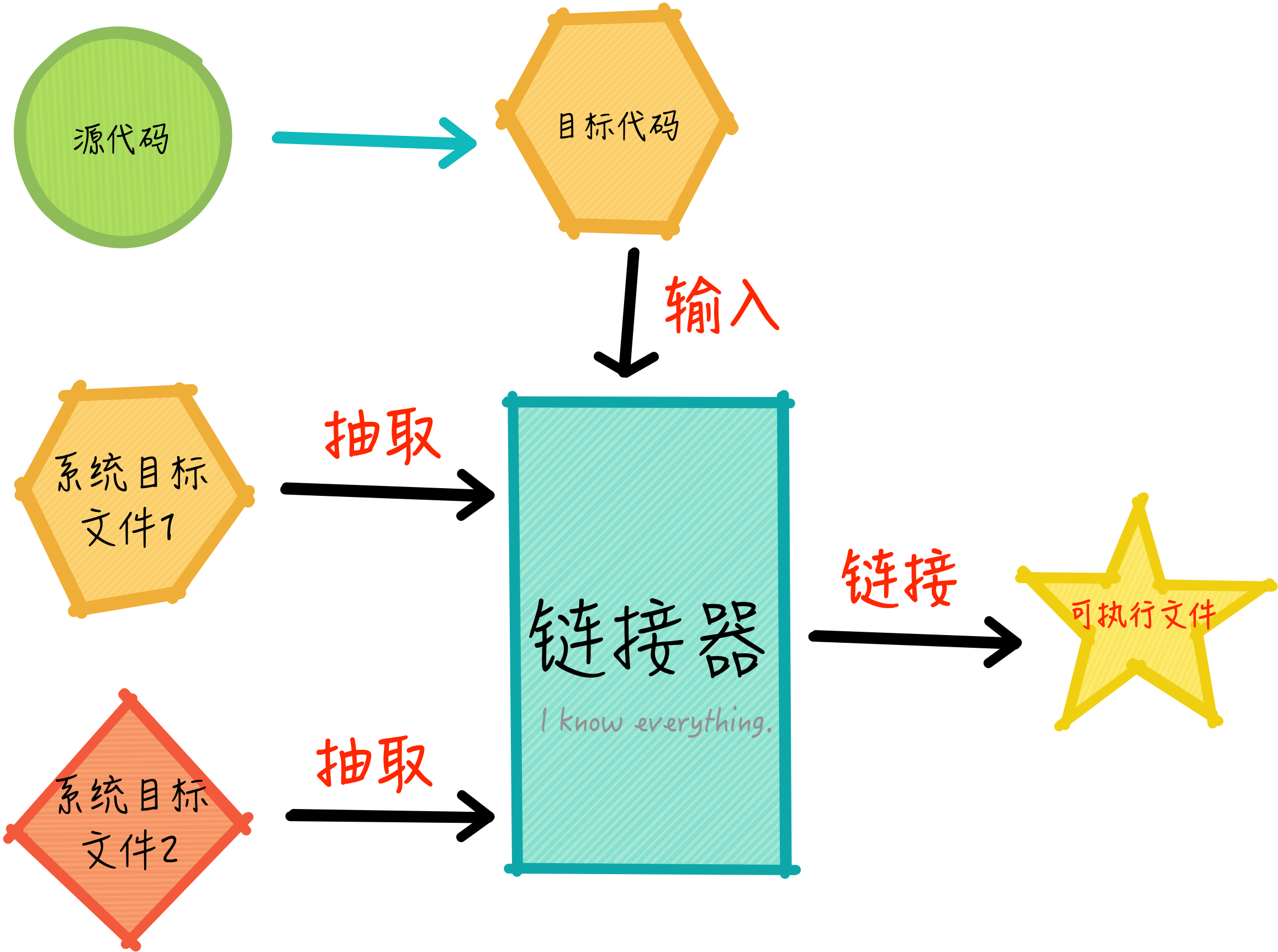
如上图所示,源代码生成了目标文件,链接器再根据源代码中依赖的线索(或提示)找到操作系统中对应的目标文件,从操作系统的目标文件中抽取出需要的部分同源代码生成的目标文件进行链接,最终生成可执行文件。
和汇编代码一样,可执行文件中的机器代码在运作时,需要访问内存,而访问内存就需要指定内存的地址,这样程序就会和硬件绑定了。为了避免硬件绑定,以及不同的程序不会产生冲突,生成的可执行文件都会使用虚拟的内存地址,而在可执行文件的头部,链接器会加上再配置信息。
可以设想我们平时开发的(服务端)应用,对于数据库连接池的配置肯定不会写死在代码中,而是放在一个配置里,代码中只会依赖其配置名,这个配置名就好比是再配置信息。操作系统会做好内存的管理,给到应用一个合适的配置,使得多个程序的运行不会相互冲突,同时让程序与硬件解耦。