程序!程序!程序!—— 硬件的执念
计算机只能够执行机器代码,也就是由0和1组成的编码,编码不是无规律的0和1,而是是由指令和数据构成的。

对于之前编译生成的gt程序,我们可以观察一下它对应的二进制编码是什么样的。使用vi工具,输入:vi -b gt载入编辑器,然后键入:%!xxd,可以看到二进制内容按照字节的格式化输出,如下图所示:

输出的二进制内容没有源码那么和善,因为它不是面向人类的,指令和数据混在一起,但早期人们写程序时,就是这样的开发环境,人手一个对照表,然后按照格式一点点的撸。后来有同学会认为这样开发的效率太低了,需要不断的查表切换,所以干脆就归纳出一套具有语义的标签,这些标签能够涵盖计算机的操作指令(包括操作计算机所关联的存储设备),这样程序写起来就方便一些了,而这些标签可以被称为助记符,使用助记符的程序设计语言就是汇编语言。
生成汇编语言
汇编语言是低级语言,它和机器语言属于同一个级别,只是有了助记符,能够让人容易理解,但是还是需要程序员像机器一样思考,通过搬运数据,指令运算来获得结果。C语言源代码可以由编译器生成出汇编代码,运行 cc -S -masm=intel gt.c > gt.s,可以获得对应的汇编代码,转换后的汇编代码如下所示:
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 12, 0 sdk_version 12, 3
.intel_syntax noprefix
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
push rbp
.cfi_def_cfa_offset 16
.cfi_offset rbp, -16
mov rbp, rsp
.cfi_def_cfa_register rbp
sub rsp, 16
mov dword ptr [rbp - 4], 0
lea rdi, [rip + L_.str]
mov al, 0
call _printf
lea rdi, [rip + L_.str.1]
lea rsi, [rbp - 8]
mov al, 0
call _scanf
lea rdi, [rip + L_.str.2]
mov al, 0
call _printf
lea rdi, [rip + L_.str.1]
lea rsi, [rbp - 12]
mov al, 0
call _scanf
mov edi, dword ptr [rbp - 8]
mov esi, dword ptr [rbp - 12]
call _gt
mov esi, eax
lea rdi, [rip + L_.str.3]
mov al, 0
call _printf
xor eax, eax
add rsp, 16
pop rbp
ret
.cfi_endproc
## -- End function
.globl _gt ## -- Begin function gt
.p2align 4, 0x90
_gt: ## @gt
.cfi_startproc
## %bb.0:
push rbp
.cfi_def_cfa_offset 16
.cfi_offset rbp, -16
mov rbp, rsp
.cfi_def_cfa_register rbp
mov dword ptr [rbp - 4], edi
mov dword ptr [rbp - 8], esi
mov eax, dword ptr [rbp - 4]
cmp eax, dword ptr [rbp - 8]
jle LBB1_2
## %bb.1:
mov eax, dword ptr [rbp - 4]
mov dword ptr [rbp - 12], eax ## 4-byte Spill
jmp LBB1_3
LBB1_2:
mov eax, dword ptr [rbp - 8]
mov dword ptr [rbp - 12], eax ## 4-byte Spill
LBB1_3:
mov eax, dword ptr [rbp - 12] ## 4-byte Reload
pop rbp
ret
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "\350\276\223\345\205\245\347\254\254\344\270\200\344\270\252\346\225\260\357\274\232"
L_.str.1: ## @.str.1
.asciz "%d"
L_.str.2: ## @.str.2
.asciz "\350\276\223\345\205\245\347\254\254\344\272\214\344\270\252\346\225\260\357\274\232"
L_.str.3: ## @.str.3
.asciz "\350\276\203\345\244\247\347\232\204\346\225\260\346\230\257\357\274\232%d\n"
.subsections_via_symbols
机器语言构成的指令代码,一般称为本地代码,本地代码和汇编代码是等价的,对应关系如下图所示:
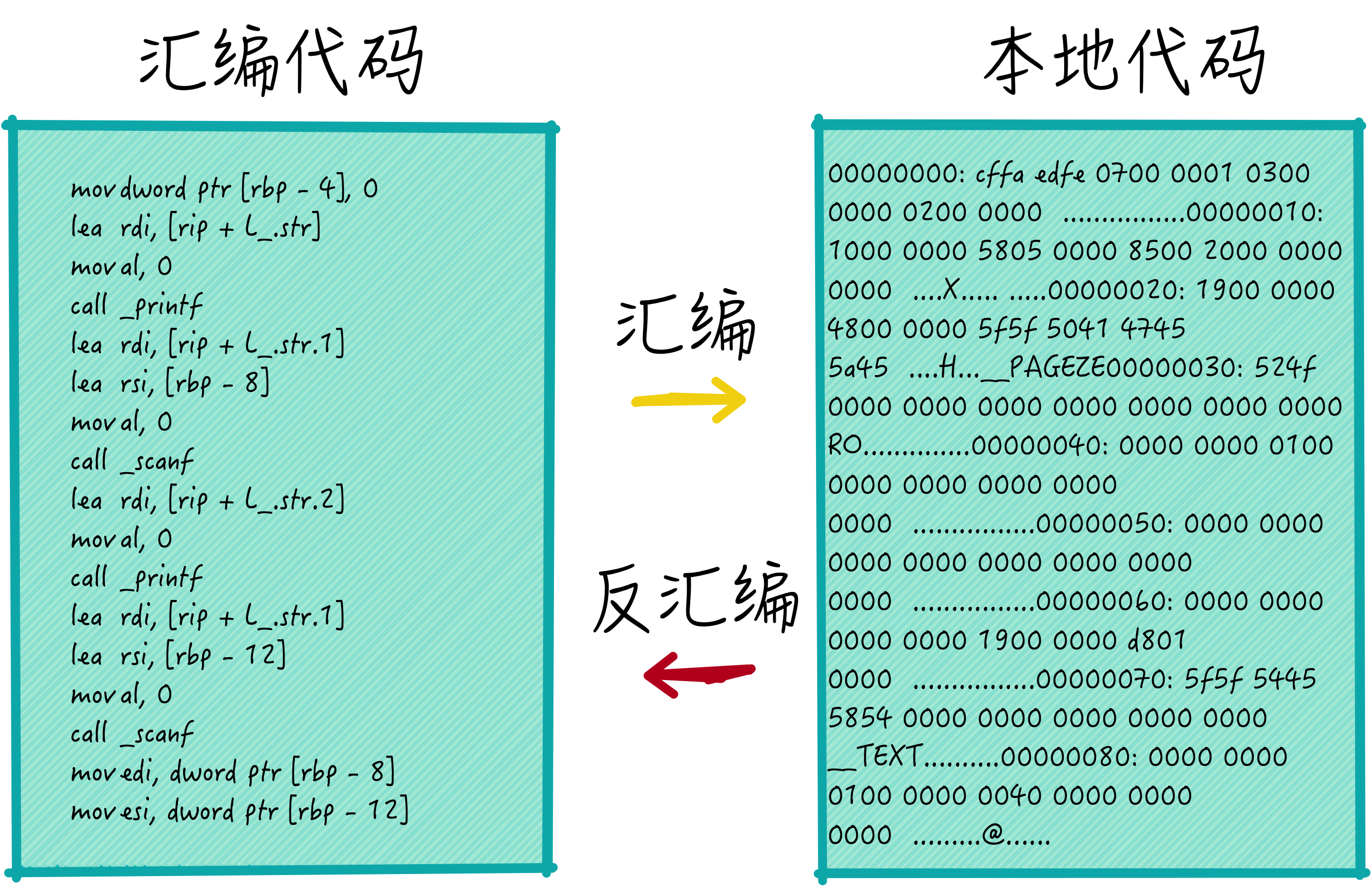
如上图所示,从汇编代码生成本地代码的过程称为汇编,反之,叫做反汇编。
什么是汇编
汇编是由助记符和操作数组成的代码,助记符一般是指令,比如该指令:mov dword ptr [rbp - 4], edi,mov这关键字就是助记符,也是指令,代表着移动,它的使用模式是:mov $target, $source。dword是修饰符,代表着double word,也就是两个词,实际就是四个字节,而$target和$source所指代的部分就没那么容易理解了。
这部分内容就是寄存器的名称,现在可以理解CPU是由控制器(CU)、运算器(ALU)和寄存器(Register)组成,而汇编语言只对寄存器做了抽象,虽说调用add指令会隐性的驱动运算器进行运算,但是实际上在汇编代码中能出现的CPU部件就是寄存器了。寄存器的种类有很多,不同的CPU架构也会有所不同,按照功能分,常用x86寄存器如下表:
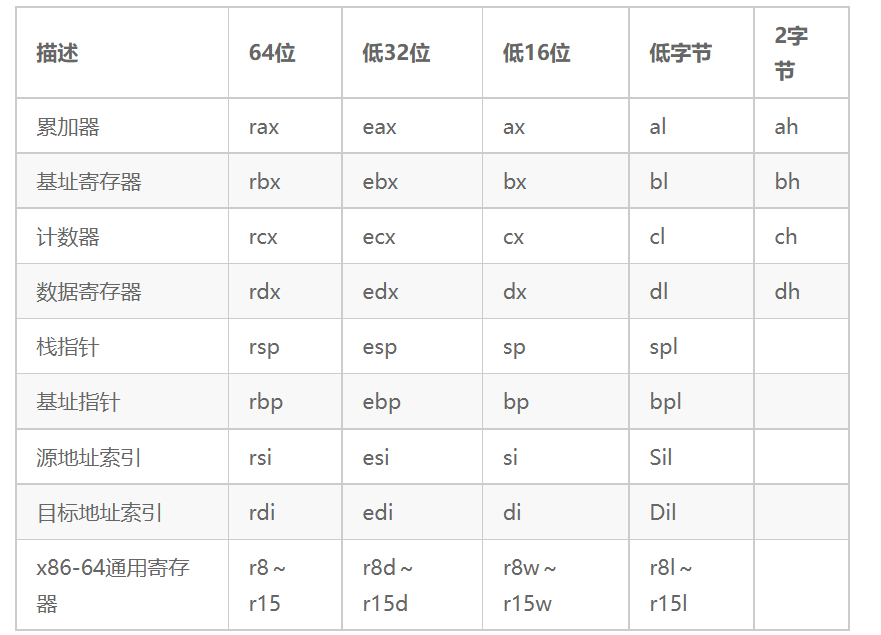
运算器会和对应功能的寄存器进行配合来完成计算,这就好比将数据(以电信号的形式)放置到指定位置(也就是寄存器的引脚)上后,方能驱动运算器进行运算,这个过程就好比武器中的步枪射击一样。

你需要将不同的数据(部件)拼好,然后再使用指令,也就是扣动扳机,来触发计算。
本文的目的不是讲述汇编语言,所以不会就汇编语言来展开,我们通过一个gt代码与汇编的对比来看一下汇编语言是如何操作硬件的。在gt.c中,有gt函数,代码如下:
int gt(int a, int b) {
return a > b ? a : b;
}
这段代码逻辑很简单,通过三目运算符,返回两个参数中,大的一个(当然如果参数相等,返回后一个参数)。类似的写法在不同的编程语言中都可以看到,大家已经见怪不怪了。接下来,看一下这个C语言函数对应的汇编代码,如下所示:
_gt: ## @gt
.cfi_startproc
## %bb.0:
push rbp
.cfi_def_cfa_offset 16
.cfi_offset rbp, -16
mov rbp, rsp
.cfi_def_cfa_register rbp
mov dword ptr [rbp - 4], edi
mov dword ptr [rbp - 8], esi
mov eax, dword ptr [rbp - 4]
cmp eax, dword ptr [rbp - 8]
jle LBB1_2
## %bb.1:
mov eax, dword ptr [rbp - 4]
mov dword ptr [rbp - 12], eax ## 4-byte Spill
jmp LBB1_3
LBB1_2:
mov eax, dword ptr [rbp - 8]
mov dword ptr [rbp - 12], eax ## 4-byte Spill
LBB1_3:
mov eax, dword ptr [rbp - 12] ## 4-byte Reload
pop rbp
ret
.cfi_endproc
## -- End function
上述汇编代码中,#号后面为注释,汇编器不会关注它。以.开头的,比如:.cfi_startproc为伪指令,表示函数定义的开始。代码由上至下的执行,先看头尾两部分的指令,即:
push rbp
mov rbp, rsp
## 略
pop rbp
ret
push指令表示将一个(rbp寄存器的)值入栈,pop指令表示出栈后将值赋给rbp寄存器。栈是一种LIFO(后进先出)的数据结构,一个CPU核心可以认为有一个栈,rsp即栈寄存器,它指向栈的顶部。上述指令相当于做了两件事情:第一件,将基址寄存器rbp的值保存到栈中,然后将栈寄存器rsp的值放入到基址寄存器rbp中,在执行完一系列操作后,会使用pop指令弹出先前保存的基址寄存器rbp值,将其设置到基址寄存器rbp。这个过程相当于保存rbp中的旧值,然后做完操作后再恢复,保证函数的执行对基址寄存器rbp是无副作用的。第二件,调用ret指令,隐性出栈一个值,并将值设置到程序计数器,也就使得函数执行完成后,执行链路能够返回到调用端。
上述指令以及函数调用的过程会在稍后章节进行详细介绍,现在如果看着晕晕的,也没关系,只需要记住
rbp是基址寄存器,可以通过它进行地址运算,而rsp是栈寄存器,它始终指向栈的顶部。
在函数体内,会移动寄存器中的值到栈上,然后调用cmp指令,cmp指令会比对指令后面跟随的两个参数,然后将比对结果放置在标志寄存器中,比对的值是一个二进制数值。根据比对的结果数值,如果jle指令判断比对结果小于等于将会跳转到LBB1_2,接着对应区块的代码会将第二个(也就是较大的)参数移动到累加寄存器eax中,该寄存器被用来承担装载函数调用返回结果的职责。
存储在标志寄存器的值包括(且不限于):是否大于,是否等于,是否小于,按照不同的位构成,方便后续的判断。
可以看到相对于C语言的几行代码,汇编代码需要一系列的指令操作,包括移动,比较和跳转,除此之外还需要用到不少寄存器,感觉复杂很多,但这其实就是计算机硬件理解程序(逻辑)的方式。
运行可执行文件
可执行文件,也就是程序,在未运行的时候,会存储在磁盘上,当运行时,需要载入到内存。从汇编代码可以看出,载入内存的程序,就像一个数组一样,当载入部分后,就可以将main函数入口的地址设置到程序计数器,随后就可以开始执行了。每执行一行指令,会增加对应的步进,重新设置程序计数器,然后CPU会根据程序计数器中的值,也就是地址信息,从内存中取出下一条指令,这样顺序执行就算做到了。程序、CPU和内存的运行时关系如下图所示:
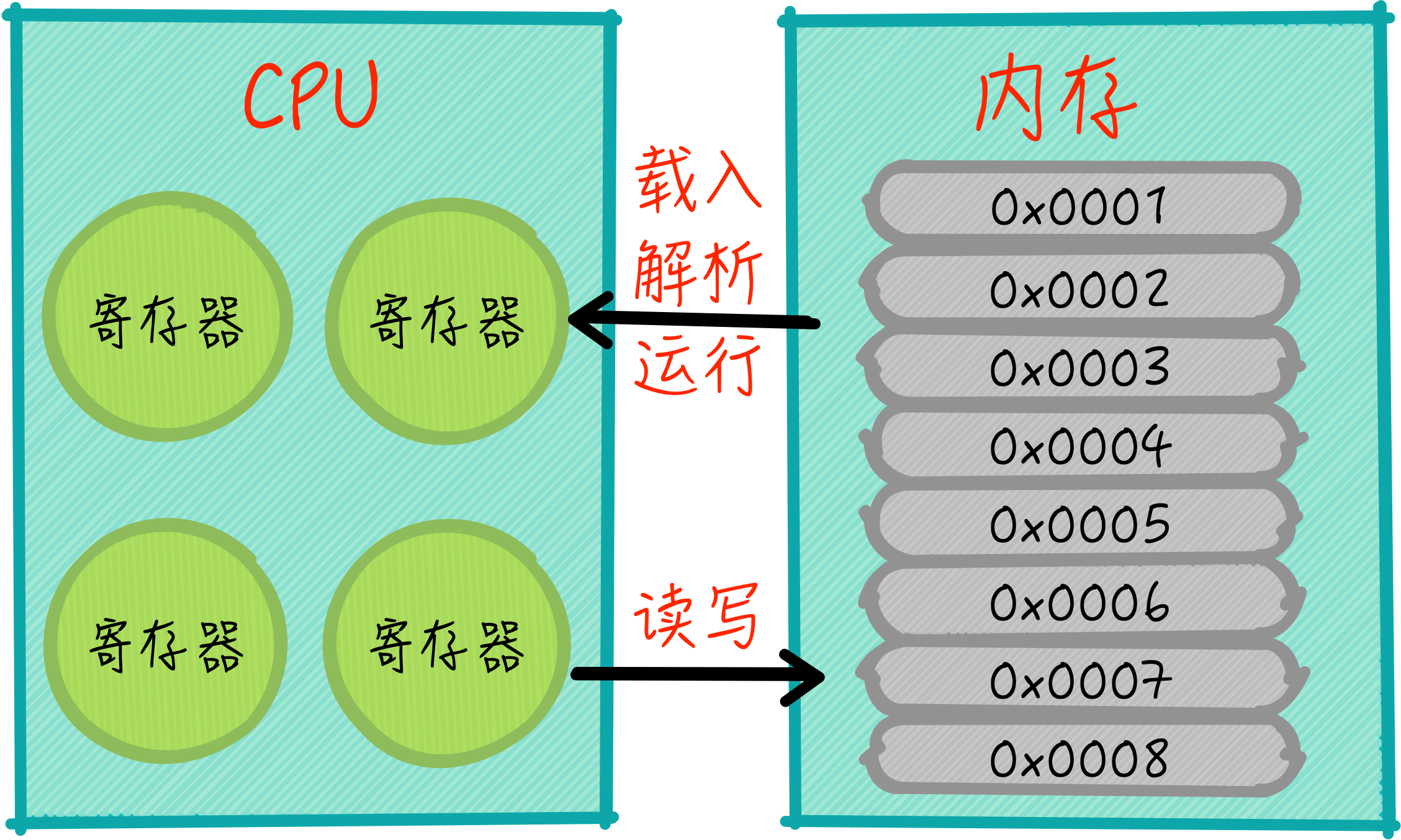
如上图所示,内存中存有程序的指令和数据,当程序运行时,CPU会从内存中读入指令和数据,再将这些内容读入到寄存器中进行处理。这里不是说CPU就把内存当缓存用,而是需要将执行的指令加载到寄存器中方能运行。如果指令中有rbp基址寄存器参与运算,CPU也会按照地址去取内存中的数据。这种由寄存器、内存到磁盘的多级存储,是现代计算机的典型结构,越靠近CPU就越快,越远离CPU数据访问的单位(或者块头)就越大,CPU访问寄存器的速度可以快到1ns,而访问内存会下降到100ns。
程序在内存中一般分为四个部分,分别是:变量、函数、栈和堆。先来说说变量和函数,在编写的程序时,代码是将变量和函数混合在一起,这符合我们的直观感受,但是编译成可执行文件后,变量和函数会被分开,放置在不同的段(segment)中。编译器这么做,听起来觉得对可执行文件的约束有些强,但实际我们费劲脑汁编写的程序不就是由数据结构和算法(函数或方法)构成的吗?而它们不就是对应着变量和函数吗?放在一起的目的是为了在内存中更加的密实,更利于缓存的命中。
在之前的汇编代码中,第一行指令
.section __TEXT,__text,regular,pure_instructions,就声明了几个段。
接下来看一下栈和堆,栈一般是由编译器生成的,在函数调用和本地变量分配时,都会使用到栈,而开发人员是无法直接感知到栈存在的。栈负责存储临时的数据,通过push和pop指令进行操作。在x86体系结构下,内存中的栈空间如下图所示:
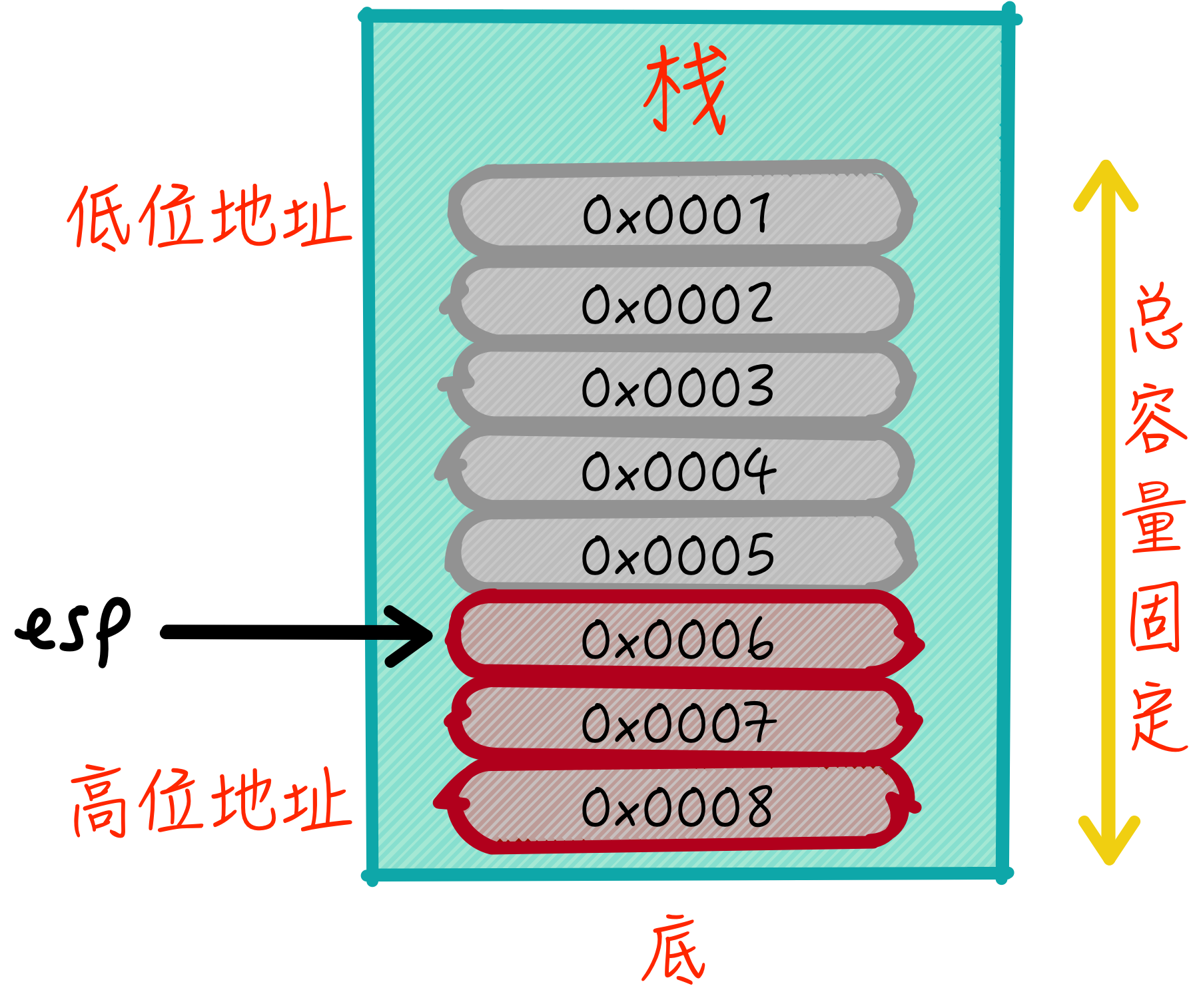
如上图所示,内存好比一个数组,栈空间会在内存中选取一块大小合适且连续的空间作为存储,一般来说栈空间不需要很大,因为它和执行线程相关,本地变量的数量有限,同时函数在调用过程中,不断的入栈和出栈操作使得栈实际的消耗是相对有限的。如果用数组的视角看栈空间,下标小(也就是低位地址)是栈顶,而下标大的是栈底,如果栈是空的,那么数据从栈底开始放置,而栈顶会随着数据的存入和弹出而不断的变化。通过push指令,可以向栈中存入一个值,栈顶会向上移动,而esp(或rsp)寄存器始终指向栈顶数据,当调用pop指令时,会将esp指向的数据取出,并将esp指向下一个元素。
以下面代码为例,函数中局部变量都会分配在栈上。
int x = 1;
int y = 2;
int z = x + y;
上述代码,在栈中的结构如下图所示:
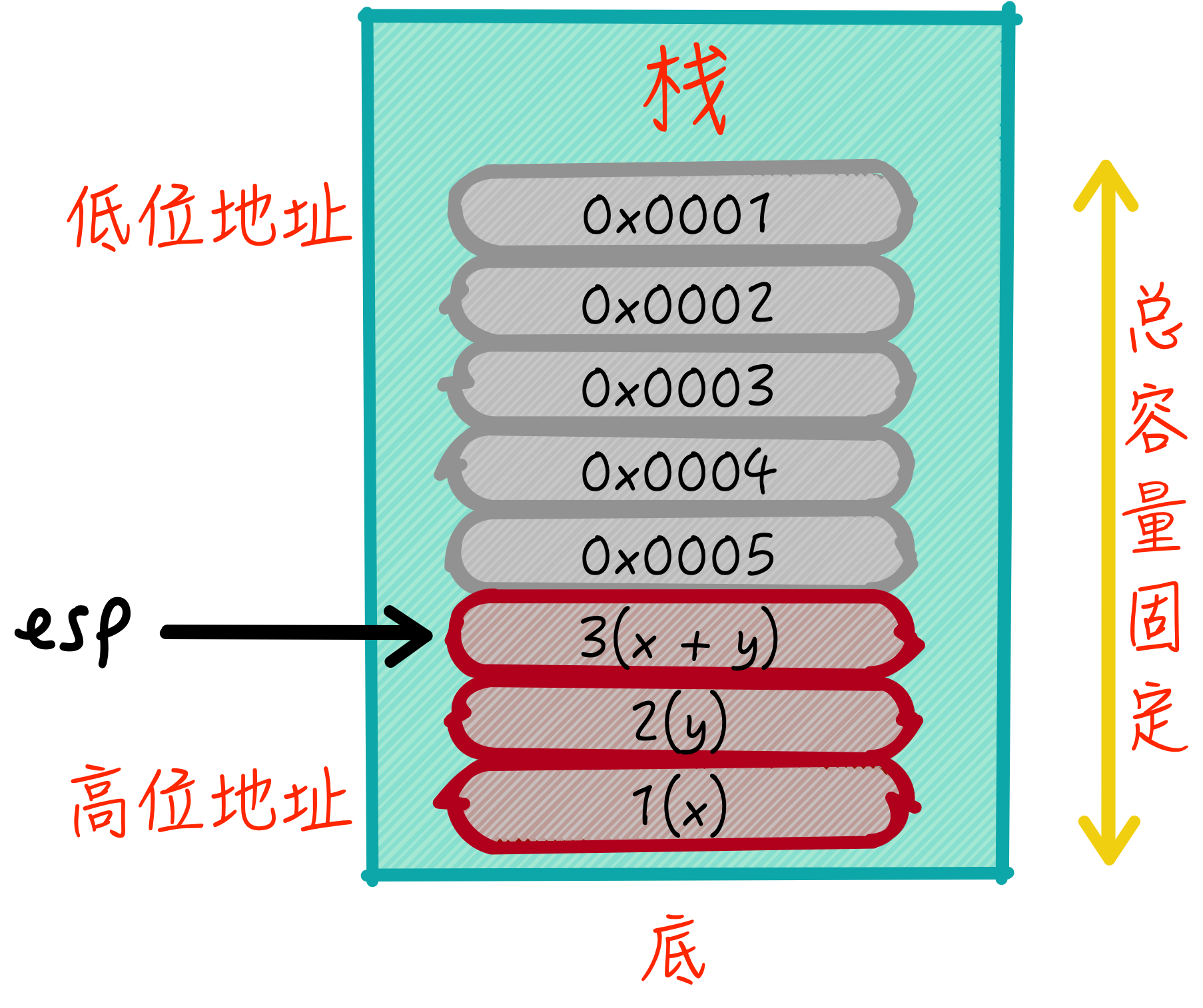
对应的汇编代码可以是:
mov ebp, esp;
mov dword ptr[ebp + 4], 1
mov dword ptr[ebp + 8], 2
mov eax, dword ptr[ebp + 8]
add eax, dword ptr[ebp + 4]
mov dword ptr[ebp + 12], eax
能够从对应的汇编代码看出,程序代码虽然可以写的飘逸,但是局部变量的分配已经在编译的时候就确定了,所以生成的汇编代码可以将我们操作任意本地变量的引用替换为地址,不论你写的多么难以理解,但你就是无法逃出如来佛的手掌心,因为你在声明变量和编写逻辑的时候,就已经将变量的类型、申请和释放告知给了编译器。
实际由于编译器的优化,汇编代码会使用寄存器来替换掉部分栈的操作,用于提升执行效率,所以对应的汇编代码只是概念上的(对等)。
另外,在main函数对应的汇编代码中,可以看到这行指令add rsp, 16,它表示将栈寄存器rsp的值增加16,也就是栈顶向下移动4个int(或者说16个字节),这样操作的结果就是不通过pop指令就完成了栈中元素的清理。
如果说栈是程序运行的内部要求,那堆就是开发者用来处理动态内存需求的工具。我们的程序运作时,会根据实际的情况来动态分配内存,不可能做到提前的预估,而对于这种动态内存空间需求,就需要使用堆。以C代码为例:
char *str = (char *) malloc(15);
通过malloc函数,也就是内存分配(memory allocate),可以开辟15个字节的内存空间用于存放数据,这个内存空间就在堆空间中。程序运行时,栈空间的大小是可知的,但是堆空间是根据程序的实际情况来计算分配的,这点对于Java程序来说,也是一致的。
程序在顺序执行中,遇到本地变量,就使用栈空间,那么不断的入栈,何时出栈呢?答案是函数调用,使用栈的原因就是它很适合完成函数调用,我们编写程序,实际就是在编写函数,从主函数main开始,不断的调用各种函数,有标准库函数,也有自定义函数。程序设计中的函数与数学中的函数有些类似,有输入和输出,函数体内部就是函数逻辑,函数逻辑依靠输入进行计算,最终将输出返回。以gt程序代码为例:
#include <stdio.h>
int gt(int a, int b);
int main() {
int a, b;
printf("输入第一个数:");
scanf("%d", &a);
printf("输入第二个数:");
scanf("%d", &b);
int x = gt(a, b);
printf("较大的数是:%d\n", x);
return 0;
}
int gt(int a, int b) {
return a > b ? a : b;
}
如上述代码所示,gt函数接受两个int类型参数,并返回较大的一个。我们观察一个场景,在调用gt函数前后,对于栈而言需要做什么。首先是参数,可以通过入栈的形式将两个变量传递给gt函数,但是调用gt函数完成后,还需要返回到调用端(也就是代码int x = gt(a, b);),这该如何完成呢?另外,如何能够让程序调用gt函数呢?这么看,实现一个普通的函数调用是相当困难的呀!可以看到,函数的调用涉及到参数的保存、控制流的变化(调用函数)、函数计算、结果返回、控制流的返回(调用函数返回)以及参数的清理,至少6件事情,这些事情肯定不是一个栈就能够做成的,它需要一些寄存器的帮助。
提到控制流的变化,就需要程序计数器的支持,而结果返回一般需要指定一个寄存器就好,常见会使用累加寄存器rax来做,当然栈寄存器rsp和基址寄存器rbp也是离不开的。首先考虑参数的保存,以示例中a和b两个参数为例,先将其入栈,考虑到函数调用后会返回,将int x = gt(a, b);,也就是函数调用后的语句地址也存入栈中,此时栈和寄存器的状态如下图所示:
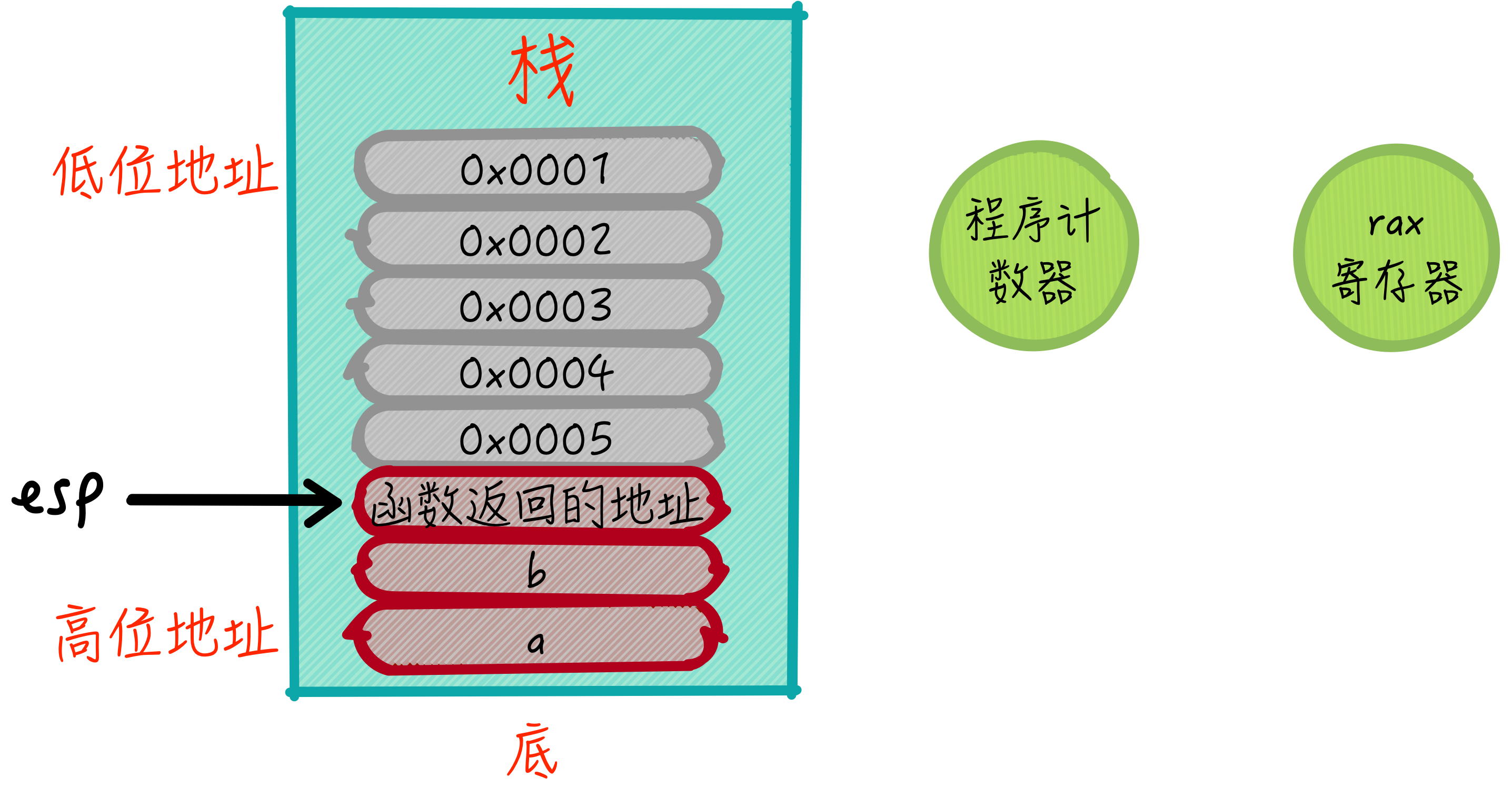
接下来,控制流的变化,也就是函数调用,需要使用到程序计数器,直接将gt函数的地址设置到程序计数器即可,在时钟调度的驱动下,CPU会取出对应的指令进行执行,此刻函数就被调用了。该过程如下图所示:
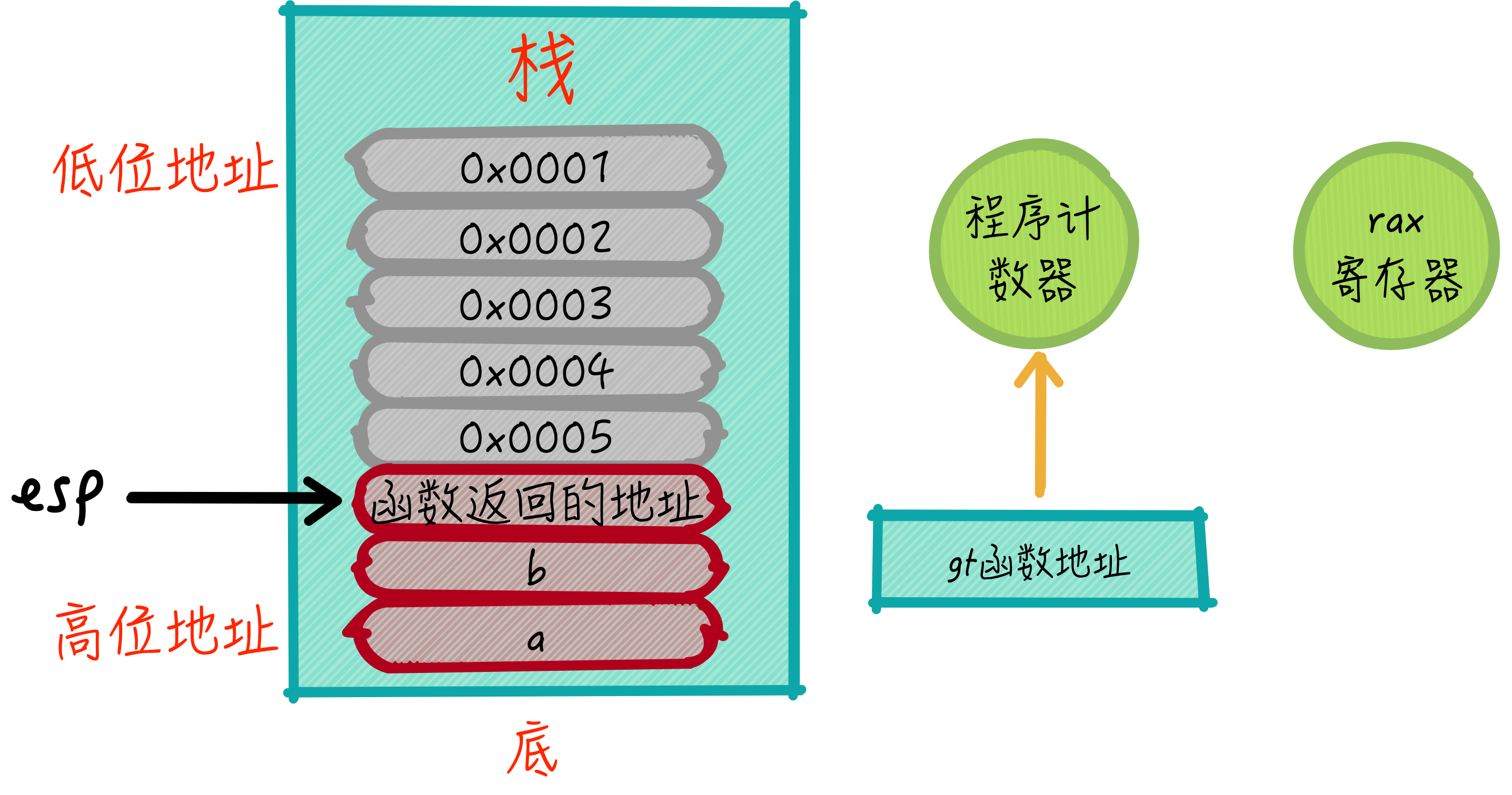
可以看到对于函数的调用,除了需要将参数入栈,还必须将函数返回的语句地址入栈,同时更新程序计数器到函数地址,而后面这两步是需要一并完成的,因此汇编代码中有对应的call指令来替代。
在函数中运行,就如同执行正常逻辑一般,只需要从栈中取出对应的参数进行使用即可,只是在函数的入口和出口,存在特定的指令模式。以gt函数为例,部分指令如下:
_gt: ## @gt
push rbp
mov rbp, rsp
.cfi_def_cfa_register rbp
mov dword ptr [rbp - 4], edi
mov dword ptr [rbp - 8], esi
// 略
mov eax, dword ptr [rbp - 12]
pop rbp
ret
## -- End function
在进入函数后,第一行指令push rbp是将当前基址寄存器的值入栈,然后将栈寄存器rsp的值设置到基址寄存器rbp中,这两条指令的目的是期望使用基址寄存器操作栈中的参数,同时将旧的基址寄存器中的值保存起来,以便后续能够恢复。在函数体中,可以看到通过类似基址寄存器[rbp - 4]的运算来取栈中的数据,[rbp - 4]表示从栈顶开始,往回4个字节的数据。
函数体末尾会通过pop rbp进行出栈,而出栈的值一定是先前在函数入口保存的基址寄存器的值,而将该(旧)值重新赋给基址寄存器,目的就是保证函数的无副作用。函数体经过执行,最终返回的值通过mov eax, dword ptr [rbp - 12]指令,将结果设置到累加寄存器eax中,调用函数后,直接从该寄存器中取值即可。
使用累加寄存器作为函数返回值的中介是C语言编译器的习惯,只需要确定使用一种合适位宽的寄存器作为函数返回值的中介即可,因为函数返回无非就是原生类型的数据或引用(指针)数据,数据位数其实都是固定的。
函数末尾除了出栈恢复基址寄存器,还需要出栈函数调用后的语句地址,并将该地址设置到程序计数器中,这样函数的执行就完成返回了。在汇编语言中,通过ret指令能够完成上述两个操作。这个特定的指令模式执行过程如下图所示:
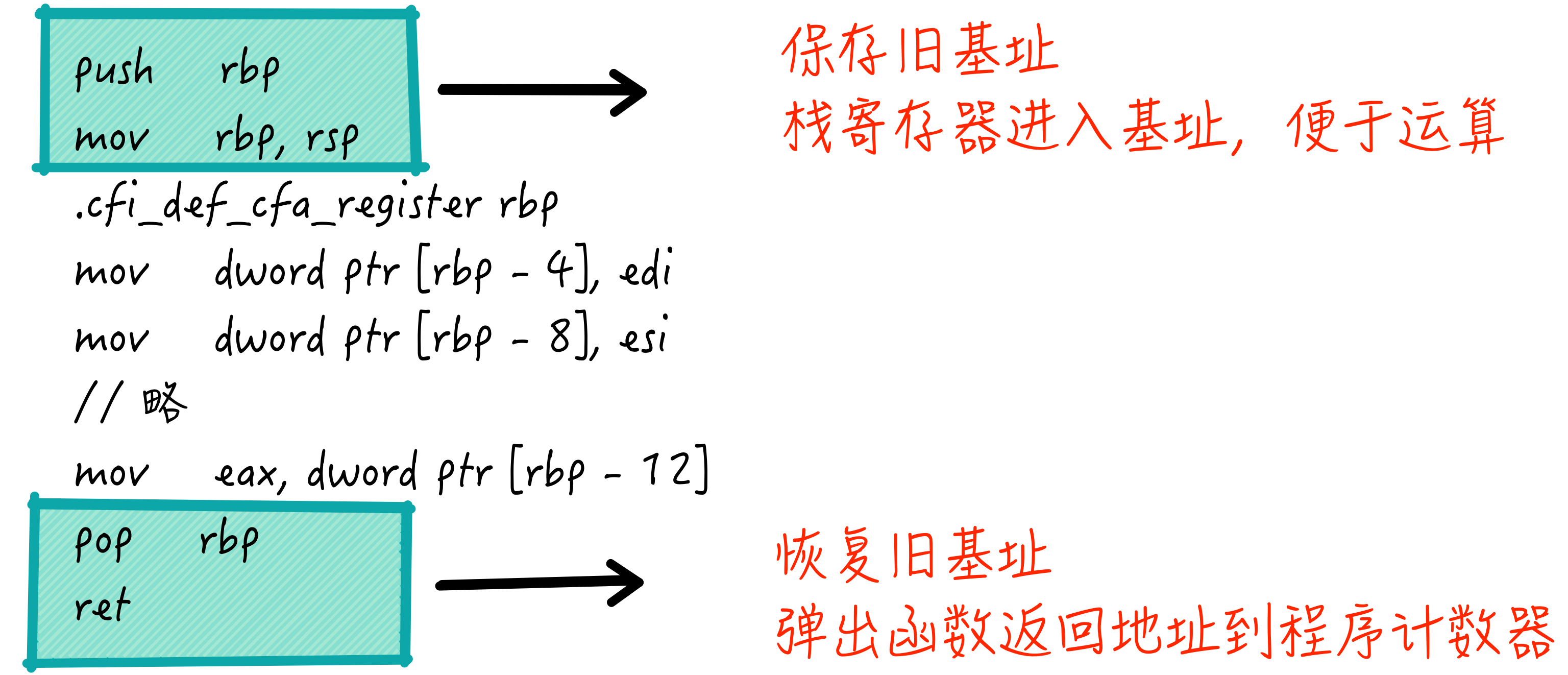
函数返回后,如果参数不再使用,会通过修改栈寄存器rsp,逻辑上忽略先前入栈的参数,这样参数的清理也就完成了。函数调用的参与者有很多,但是明确了它们各自的职责后,会发现这个过程是很考究且有趣的,通过栈以及几个寄存器的配合,就可以使用计算机运行的基本原理包装出函数调用,而函数又是面向开发者的有力抽象,仔细想想,设计者真是很聪明啊!