感悟《计算机网络:自顶向下》(4a.网络层)
开发者平日能够触及到的网络最底层也就是传输层了,因为网络编程界面,也就是socket,就属于针对传输层的抽象,目的就是为了完成数据从A到B的传输,无非传输方式是采用可靠的TCP还是不可靠的UDP,只需要在使用socket时做好选择就可以了。其实从网络层看来,TCP协议或者UDP协议,都只是建立在IP协议上的一种策略应用,但由于两个协议格式完全不同,所以二者是有排他性的。
如果用现在的观点去看TCP/IP协议,在传输层这一块,设计的很一般。TCP协议具备面向连接、可靠传输、流量控制和拥塞控制等特性,而UDP则是IP协议上兑现了进程到进程的薄薄一层抽象,其实应该有简洁一致的传输层协议,将进程传输、可靠、流控、拥塞控制和安全等特性以插件的形式组装到协议本身,而传输层协议就会变成一个体系,而非面向功能支离破碎的产物。就像谷歌在HTTP/3.0中又在玩UDP一样,面向互联网的UDP要做到可用,流控和拥塞控制又要重复建设一遍,有点蠢。
经过传输层,就到了网络层,它是解决主机到主机传输问题的,需要将报文(Datagram)以分组(Packet)的形式,从一台主机传输到另一台主机,而两台主机并不一定在一个子网中,这就需要考虑组网的形式以及传输的方式。网络层从功能层面分为两个部分,即数据平面和控制平面,听着和叫好不叫座的ServiceMesh很像,其实它们分别对应转发和路由,从先后顺序来说,应该是ServiceMesh抄网络层的概念。
转发,指的是分组从一个端口进入,然后从另一个端口输出。转发属于网络层的局部功能,在任意分组交换设备上,一般会同时具有多个端口,每个端口会连接对应的主机(或分组交换设备)。连接着分组交换设备的主机顺着端口发送分组,分组交换设备将分组收下,根据分组的目标地址进行路由计算,得到目标端口,然后将分组转发到目标端口上。
路由,是决定分组传输路径的全局功能。两个主机之间进行分组传输,分组需要通过多个分组交换设备,这就要求每个分组交换设备虽然可能是不同厂商生产的,但是由于它们之间由物理链路直接或间接连接,那么就一定可以使用一致的路由算法,使得分组能够顺利通过若干节点,抵达目标主机。
数据从路由器某个端口入,某个端口出,路由器实现数据平面和控制平面的方式有两种:第一种是目标地址+路由表的传统模式,第二种是基于分组中多个字端过滤+流表的软件定义网络SDN模式。

如上图所示,传统路由器的数据平面和控制平面紧耦合,数据转发依赖控制平面提供的路由算法,而路由器之间通过特定的协议进行子网信息交换,各自独立的维护着路由表,路由表会在分组路由计算时发挥作用,而整个过程就像大洋上航行的轮船,相互之间只能看到最近的几艘船,船队的整体方向难以掌握。
虽然这种模式去除了中心依赖,但是想要对网络进行宏观维护就变得困难,因为任意节点的调整引起的涟漪是不可预知的,尤其是在网络规模越来越大的前提下。
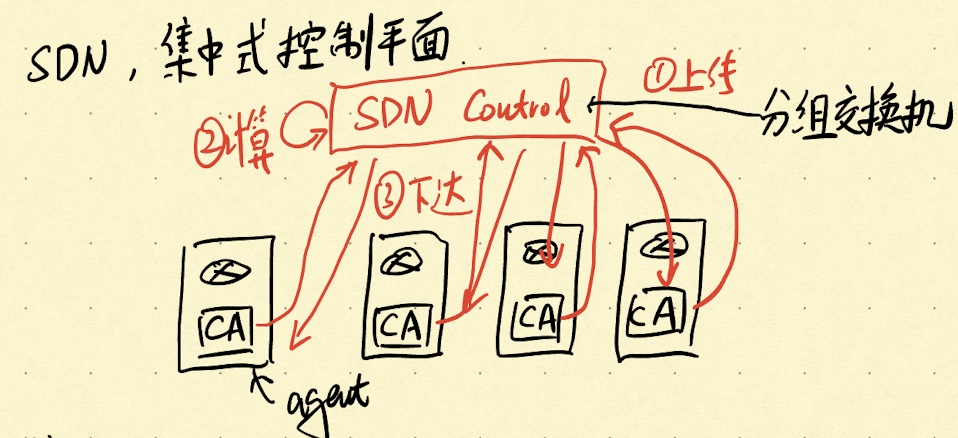
如上图所示,SDN模式是一种集中式的网络控制模式。它要求在各个路由器上部署agent,路由策略上传到分组交换机上,由分组交换机完成路由计算,并将计算结果下发到各个路由器上,当然每个路由器上的agent都会时刻将状态信息汇报给分组交换机,这样它在计算时就能做到有的放矢。这么一看SDN有点像分布式服务中的服务发现呢,其实除了名字换一下,大致流程都差不多。
无论是数据平面的转发,还是控制平面的路由,在处理过程中需要依凭的信息就是网络层的IP地址,IP地址是任何分组交换设备(也包括主机)的状态信息,可以简单的认为在分组交换网络中,控制平面中路由器的路由表以及分组交换设备的IP地址是各自设备上的状态信息,任何转发和路由,都要基于状态信息。路由表信息中的路由规则也包括了IP地址信息,所以我们先来看看IP地址。
其实任何分组交换设备,包括主机,都同时具有路由表和IP地址信息。
IP地址
IP地址目的是标识一个分组交换设备,无论它是一台主机还是一个路由器,如果给定了一个标识,就能定位到它。假设从定位资源的角度出发,IP地址可以使用一个数字类型的值来表示,比如:2333表示的是某一台位于杭州的主机,可是IP地址设计的目的没有这么单纯,它需要完成以下多个工作:
- 标识设备,IP能够定位唯一的设备,报文的来源和目标都需要基于这个标识,也就是IP;
- 关联承载网,IP是软件概念,或者说它是构建在不同承载网上的抽象,依靠IP能够完成不同承载网之间的互联互通,这是IP地址前期最重要的使命;
- 实现路由,在分组交换网络中,任何分组交换节点对于分组均采用存储与转发的方式进行处理,而转发(或者说路由)的前提就是基于IP。
关联承载网是能够通过IP协议设计以及承载网自身实现的努力适配做到,一定程度对IP地址的细节没有过多要求,比如:ARP协议,它属于数据链路层(或者说以太网这个承载网上),提供将IP地址转换成为MAC地址的服务,其中MAC地址是属于以太网的概念,IP并不知情。
如果IP地址用整型,标识设备这个工作也没有多少问题,操作系统可以支持指定或者自动获取的方式来设置网卡设备的IP地址,实现设备的标识。路由就没有这么简单了,如果IP地址是一个整型数字,实际上它就是,那么两台主机间存在的路由器势必要记住所有的IP地址,比如:IP地址为1到2000,向端口1转发,IP地址为2001到100000的,向端口2转发。可以想象,如果使用IP离散的标识设备,对于主机间的路由设备而言,将是灾难的,因为它们无法存储这么多地址与端口的对应关系。
地址与端口的对应关系就是路由表,路由表的尺寸必需缩小,能想到的方式就是将需要路由的条件和地址分离,通过缩小路由条件的规模来缩小路由表,这就需要赋给IP地址一些特殊的意义,也就是子网。可以将一个IP地址分为两部分,第一部分是子网,第二部分用来描述子网中的主机号,这样放在一起能够定位到主机,分开进行路由时,就只用关心子网。
因此,一个IP地址需要表达两个含义:第一,子网编号;第二,主机号。
如果对于一个数字,需要能够同时表述两个含义,可以通过规定特定的位数来分别表示二者,比如:前N位表示子网,后M位表示主机。这样一个分组需要发往目标IP地址,就可以通过N位子网信息来确定该从哪个端口输出,而N位子网数据是相对有限的,并且子网就是一组高位相同且无需路由器介入,在物理上相互可达的网络。
IP地址(的V4版本)选择使用32位的整型来描述,如果是十进制表示,也就是最大能够描述40亿左右的设备,可是一旦加上子网的概念,数量就会急剧下降,毕竟某些子网中的主机数不会全部使用。如果要在数字上进行按位赋予含义,二进制相比十进制是有些许优势的,比如:指定前8位为子网,后24位为主机号,但是一个子网内是不可能存在1600多万个主机,也就是由24位二进制描述的主机的,所以IP地址就需要进行一些规划,目前常见的两种规划方式:地址分类和无类域间路由(CIDR: Classless Inter Domain Routing)。
地址分类
IP地址分类的思路非常直截了当,它由三部分组成,第一部分是类别,它是固定的,第二部分是根据类别约定的子网,剩下的第三部分就是主机了。地址分类下的子网与主机数如下所示:
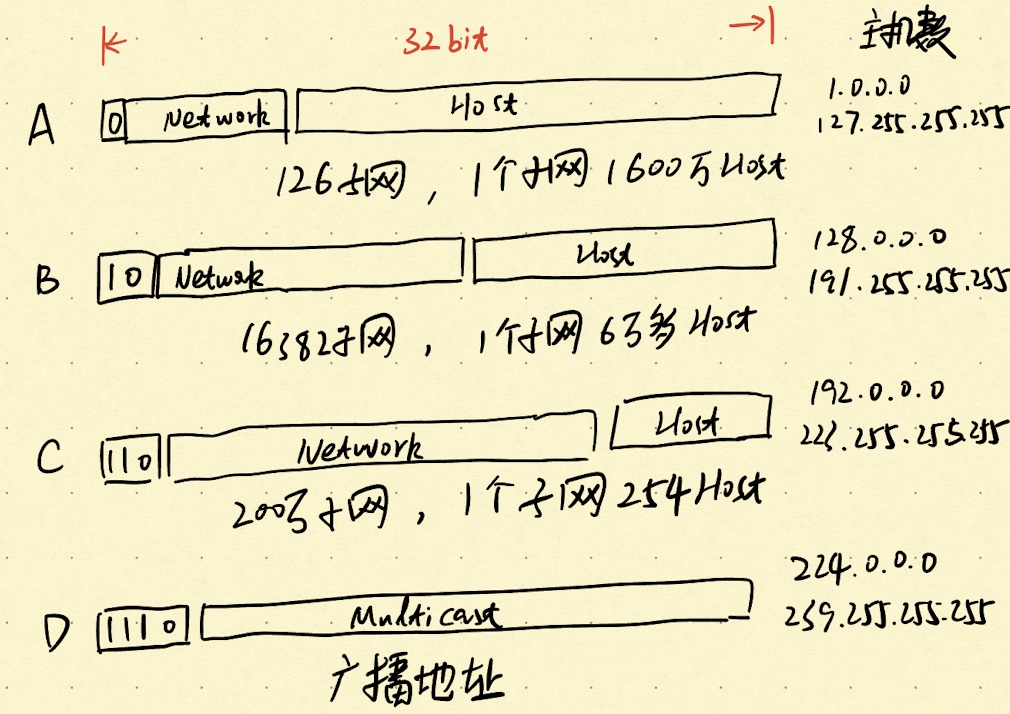
可以看到地址分为4类,分别是:A,B,C和D。A类地址是最高位为0,对于A类地址描述子网的是接下来的7位,也就是A类地址能描述126个子网,每一个子网可以包含1600万个主机,比如:用点分十进制描述的1.1.1.1,这个IP就属于Cloudflare维护的DNS服务器。A类地址规模太大了,B类地址就收敛一些,对于最高位是10的,那么接下来14位用来描述子网,剩下的16位描述主机,也就是允许规划16382个子网,每个子网可以最多容纳6万多个主机。
B类地址看起来友善许多,很多大公司或者机构都开始申请,比如:128.255.255.1,这个IP就属于美国爱荷华大学,如果再仔细看一下,其实128.255这个子网下,6万多个IP都分配给了爱荷华大学,也就是128.255.3.3这个IP也属于爱荷华大学。1万6千多个B类子网,也是胡乱分配完成了。
早期在进行IP分配时,往往以分类子网的形式,将一个子网分配给机构。比如:IBM就拥有A类地址,但是IBM怎么可能有1600万台主机呢?
更多的组织或者企业其实也就是几十上百台主机,它们要求自己的主机在一个子网中,这就要求需要IP地址倾斜更多的位数到子网,因此C类地址就出现了。它以110开头,随后的21位描述子网,最大可以支持200多万个子网,每个子网可以有253个主机。比如:192.192.192.192就属于中国台湾省屏东县的大仁科技大学。
D类地址是用于多播的,也就是以1110开头,后面的28位均用来描述子网,而A,B和C类地址是单播。根据IP地址的前4位可以判断IP类型,通过IP类型再使用对应的逻辑可以找到子网与主机。
私有地址
在介绍无类域间路由之前,先谈一下私有地址。随着支持IP的设备越来越多,适配IP(或者说基于socket)能够提供面向网络的软件生态快速发展,企业或组织有自建网络的需求,同时这个网络可以不连接到互联网,只用于企业或组织内部。
通过使用NAT,能够支持内部网络(或者说私有地址)与互联网的互访。
IP设备成为了国际标准,在不同国家的市场上,兼容IP的设备和软件不断涌现,这就产生了一个问题,IP地址不够了。由于之前IP地址分配的随意性,导致新的企业和组织无法获得有效的IP地址,连自己组网的需求都无法完成。这时负责网络的标准化组织想到一个主意,从现有IP地址池中拿出一些还没有分配出去的地址,让这些地址能够给到不同的企业或者组织使用,只需要让这些企业或组织保证在自己的子网中IP地址不冲突即可,而不同的企业或组织可以拥有相同的IP地址。
私有地址从A,B,C类地址中各拿出了一部分,如下所示:
A类:10.0.0.0 ~ 10.255.255.255,1个子网
B类:172.16.0.0 ~ 172.31.255.255,16个子网
C类:192.168.0.0 ~ 192.168.255.255,256个子网
通过在ipshudi.com上查询10.10.10.10这个IP,可以看到如下内容。

如上图所示,可以看到10开头的A类地址是私有IP地址,如果使用过云服务,可以看到内网IP一般都是10开头,这表示云服务厂商为了支持很大的节点规模,从而选择10这个网段。
如果在类UNIX系统中,可以使用whois命令来进行查询。
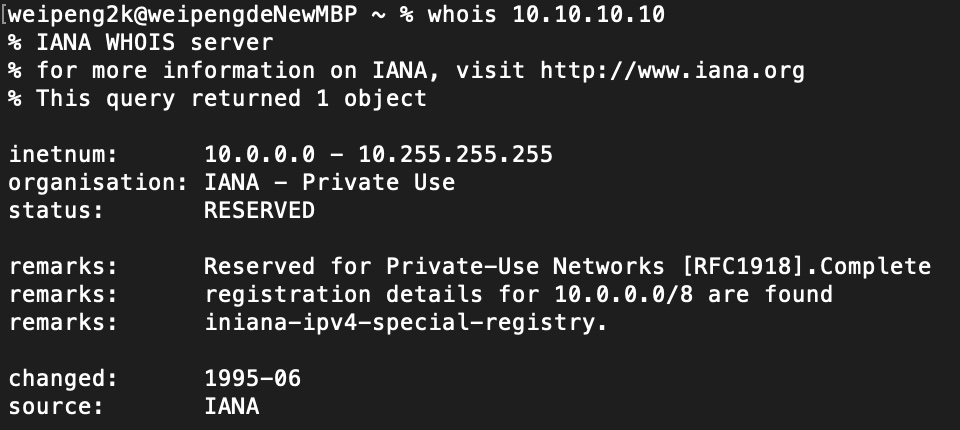
查询10.10.10.10这个IP,可以看到该IP属于Private Use,代表它是一个私有地址。
全局地址
IP地址在设计之初就是面向全局的,每个支持分组交换的设备都拥有一个IP地址,毕竟有上亿的IP地址,应该是足够的。随着接入互联网的设备越来越多,相同的IP会导致冲突,数据无法进行路由,因此IP地址需要进行管理,管理它的组织就是ICANN(Internet Coporation for Assigned Names and Numbers),在中国这个组织就是CNNIC。
当需要接入互联网的组织或企业进行互联网接入时,就需要向所在地组织申请IP地址。
无类域间路由
一个IP地址由子网和主机号组成,在一个子网内,多个主机能够相互通信,同时不同子网的IP地址也能够通过路由器的分组转发做到互联互通,一方面子网提供了部分主机的管理诉求,另一方面按照子网进行分组路由达成了数据互通的目标,这就是IP网络最开始的朴素愿景。
最开始IP地址分配按照类来进行的,比如:类似IBM这种企业,轻易的就拿到了A类地址,这也就是说它的一次申请,拿走了1600万个IP。通过这个例子可以看出,技术没有问题,但是治理上却糟透了。由于大量的企业不能申请A类地址,转而疯抢B类地址,因为C类地址的主机数不够用。
这样看来按照分类去规划IP地址的方案不能继续了,需要一个方案能够在一个A类地址基础上,将其切成更小的块,简单说就是子网变大。比如:对于11开头的A类IP地址,可以将前2个字节都算作子网,这样IP地址的利用率就提高了,因为11开头的IP地址可以被分拆最多256个子网。
那问题就变成了如何确定子网有多大,这就是无类域间路由(Classless Inter-Domain Routing)的工作了,它通过使用子网掩码来解决这个问题。
对于10.10.10.10这个IP,10是子网,而10.10.10是主机,但通过设置子网掩码为255.255.255.0,也就是高24位为1,可以将这个IP的子网设置成10.10.10,而主机号是10,这样一来,子网就多了。
特殊地址
还有一类IP地址很特殊,它们被保留下来,比如常见的127.0.0.1,这种以127开头的地址称为回环地址。
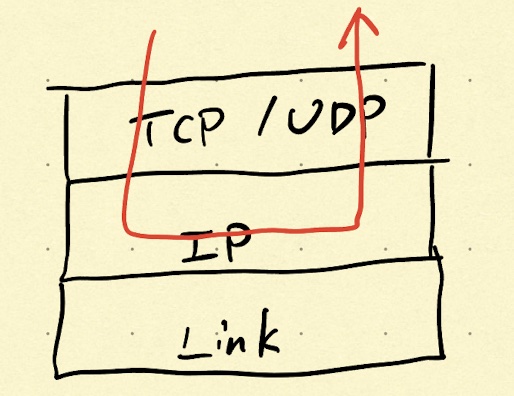
如上图所示,来自传输层的报文,经过网络层后,如果发现目标地址是回环地址,就会将数据反向发回去,回环地址的存在极大的方便了网络程序本地的开发调试。
获取IP地址
现在的计算机都离不开网络,而且还是基于IP的分组交换网络,这就需要操作系统启动后在子网中拥有独立的IP地址。有两种方式获取IP地址,一种是手工设置,另一种是通过DHCP(Dynamic Host Configuration Protocol)。
先看一下手工设置,在操作系统中一般可以配置IP地址和子网掩码,这个IP地址是使用者自己指定的,如果子网中已经存在想要设置的IP地址,某些系统会给出提示。如果系统启动后需要访问互联网,手工设置还需要配置网关和DNS服务器,前者一般是路由器IP地址,为了提供向外部网络路由的入口,后者提供域名解析服务,往往也是路由器IP地址,因为在路由器上会运行DNS服务端。
接下来是DHCP,它提供了一种从DHCP服务器获取IP的能力,主机不需要指定IP,而是由一个服务节点来进行分配,这个服务节点保存和管理了当前子网中所有已经分配的IP。当系统启动时,系统通过DHCP客户端向子网进行广播,请求IP地址分配,因为客户端此时并不知道服务端的具体位置。DHCP服务端收到客户端发来的广播请求后,会以单播的形式提供给客户端Offer,比如说:你可以使用192.168.31.111这个IP,子网掩码设置为255.255.255.0等。DHCP客户端收到Offer再进行申请操作,分配过程才算完成。
一般来说DHCP服务端在子网中往往部署在路由器上,运行端口是67,协议采用UDP,可以通过nc命令进行查看。

如上图所示,使用nc -uz尝试连接目标IP的UDP端口,可以看到能够成功连接到路由器的67号端口,而输出文本中的bootp就是DHCP协议的前身。
IP协议
IP地址与路由器(或者任意分组交换设备)中的路由表,是网络层状态的体现,前者用来描述具体的分组交换设备,后者用来指引对分组的存储转发。这里提到的分组,就是Packet,它是面向字节的,虽然看起来都是0和1,但是它是符合一定规范的,这个规范就是IP协议。
IP协议定义了在分组交换网络中传输数据的格式,它设计的较为紧凑,在展示IP协议格式时,还是先想清楚设计它的目的是什么?分组交换设备之间进行点对点的数据传输,这里的点对点不是相同子网内的两点,而是跨子网的两点。如果要设计分组交换设备之间的传输协议,首先需要指定发送方的IP地址,然后是接收方的IP地址,不可避免的还需要包括针对传输数据长度以及当前分组起始位置的描述,最后还要包括传输数据的种类以及当前分组的序号,这样看来至少要有6个属性。理解了想象中的IP协议,那就看看现实中IP(v4版本)协议的格式,如下图所示:
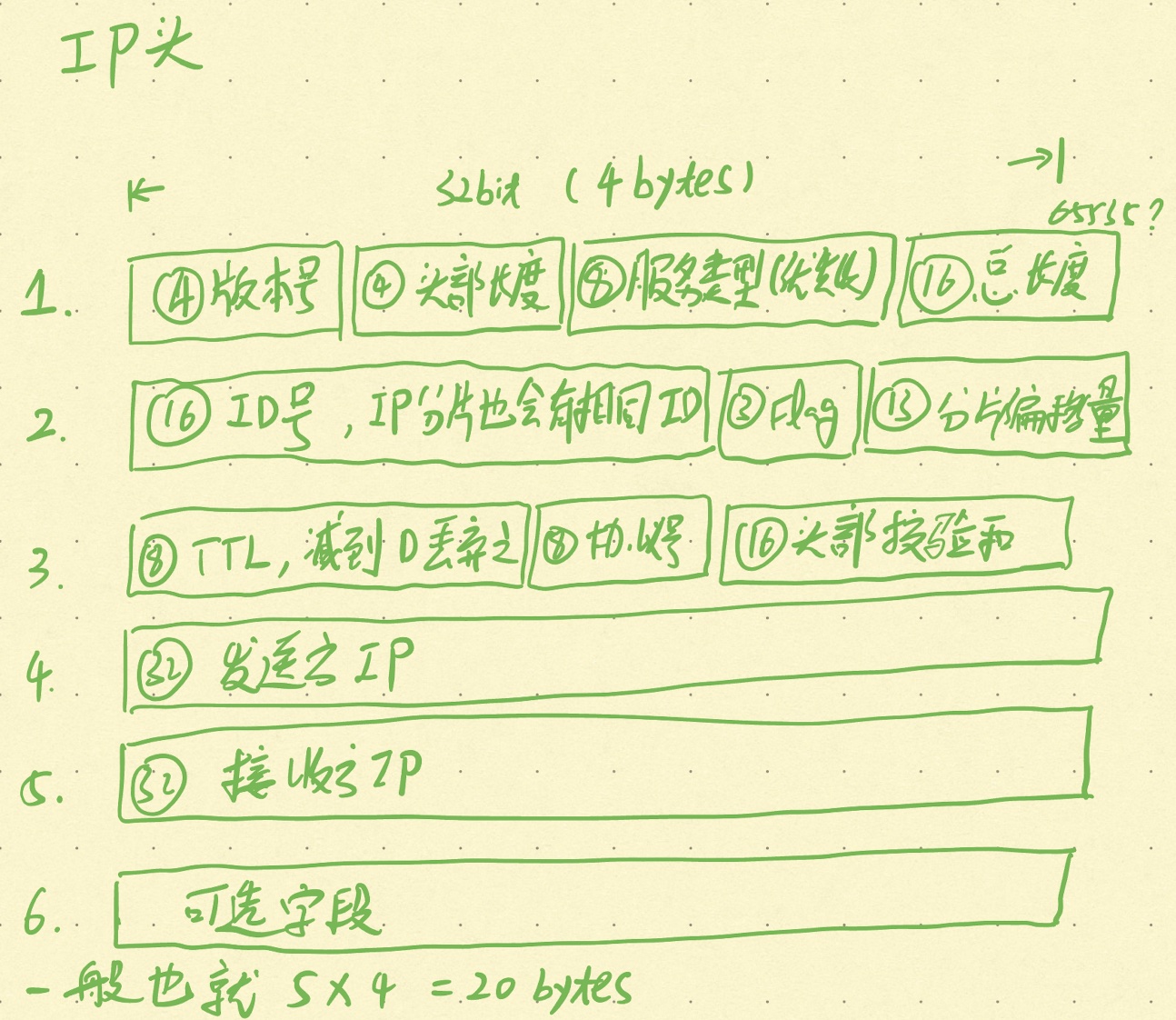
如上图所示,可以看到除了可选字段,有12个属性,比我们预想的要多一些,主要多了哪些呢?
| 名称 | 比特长度 | 描述 |
|---|---|---|
| 版本号 | 4 | 描述IP协议的版本 |
| 服务类型 | 8 | 分组的优先级 |
| Flag | 3 | 分片的标志位 |
| 分片偏移量 | 13 | 如果IP分片,当前分组处于的位置,目的是将数据能够在对端拼起来 |
| TTL | 8 | 存活时间,一般是个正数,每次经过一个分组交换设备时就-1,如果到0就丢弃该分组 |
| 头部校验和 | 16 | 针对IP协议头部的校验和 |
可以看到多出的6个属性,除了版本号以及TTL,其他4个没多少价值。以服务类型为例,分组交换设备本来处理分组的方式就是存储与转发,在设备内维护了队列,如果你指定了某个分组的处理优先级,难道还要求后面链路中的所有分组交换设备都按照你的要求处理?使用优先队列的方式?太复杂了,加重了转发设备的负载和空间开销。Flag和分片偏移量用来描述当前分组是否进行了分片,以及所处的位置,二者按位合并到一个属性中即可,或者放到可选字段中,因为基于TCP传输的应用压根不会分片,16个比特完全被浪费了。头部校验和更没有存在的意义,因为TTL一直在变化,让链路上的分组交换设备一直比对,再设置新的TTL,重新计算校验和完全是浪费资源。
版本号对于协议向前兼容是有价值的,TTL为了防止网络中出现环,定义分组的生命周期是很有必要的。所以这么看来IP(v4版本)协议设计的也就这样,一般般。
4比特的IP头部长度和16比特的总长度,可以计算出IP分组携带的数据长度,也就是用后者减去前者。头部长度的单位不是字节,而是4个字节,是不是有点意外?这点与TCP协议的头长度单位一样,有点草台班子的感觉,不过也不用在意这些细节。
一个IP分组理论上最大载荷在65K字节左右。
协议号长度是一个字节,比如TCP协议的值就是6,UDP是17,支持的种类是挺多的。IP协议本质上也是变长头和变长体,通过给出头大小以及总体积来实现。
ID号与分片
IP协议中包含了ID属性,这个ID属性与TCP协议中的sequence差不多,代表着当前分组的编号,它可以是不断自增的。由于IP协议的目的是完成主机之间的数据传输,如果使用IP协议传输超过IP协议长度(或者说超过链路层MTU)上限,就需要进行分片,否则就需要使用IP协议的用户自己切分数据,那就太麻烦了。
对于跑在IP协议上的TCP,它需要保证自己一个报文不能被切成两份,因为对于TCP而言,TCP报文头太重要了,所以IP分片对于TCP来说没有什么用。TCP的实现会调用IP获得当前(以及对端)所能支持的MTU,并小心翼翼的将报文尺寸控制在MTU之内,避免出现分片。
对于UDP而言,传输的数据尺寸就没那么多讲究,一堆byte交过来,就要进行传输,IP协议就会在超出限制时,选择分片。多个分片之间的ID是相同的,是否分片由Flag属性描述,同时当前分片所在位置由分片偏移量来指定。
数据Padding
头部长度单位是4个字节,所以IP协议的头部需要凑个整,如果一个IP分组的头部包括一些可选字段,那么就需要在可选字段基础上,做好对齐。
IP分组头部的字节数是4的整数倍,如果不足,就补齐。
查看一个IP包
使用wireshark随意抓一个IP分组,可以看看IP协议对应的属性是什么。抓到的IP分组如下图所示:
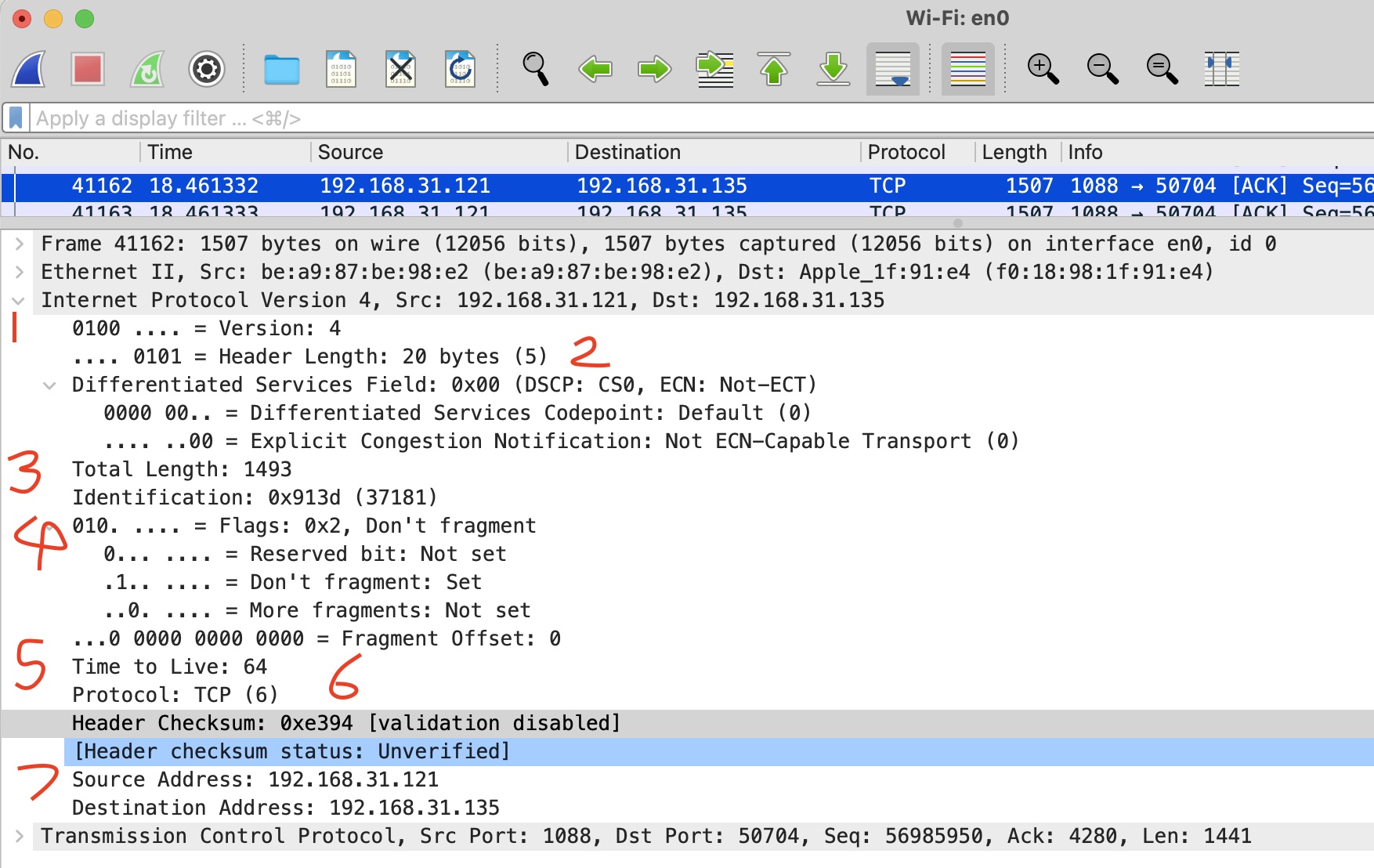
如上图所示,展开IP部分,按照序号从上到下看一下。
- 版本,可以看到当前IP分组的版本是4;
- 头部长度,值是5,也就是20个字节,常规IP头部都是20个字节,没有啥可选字段;
- 总长度,1493字节,小于以太网的MTU;
- 分片属性,不分片;
- TTL,初始值一般是64,也就是允许有64个HOP,能跳64下;
- 协议号,值是6,代表内部装的是TCP报文;
- 发送方和接收方IP,两个端点的IP地址。
从IP报文的头部校验和属性描述可以看到,压根就不会对这个属性做校验,是忽略的,该属性没什么用。